




Today we’re introducing Mistral Small 3, a latency-optimized 24B-parameter model released under the Apache 2.0 license.
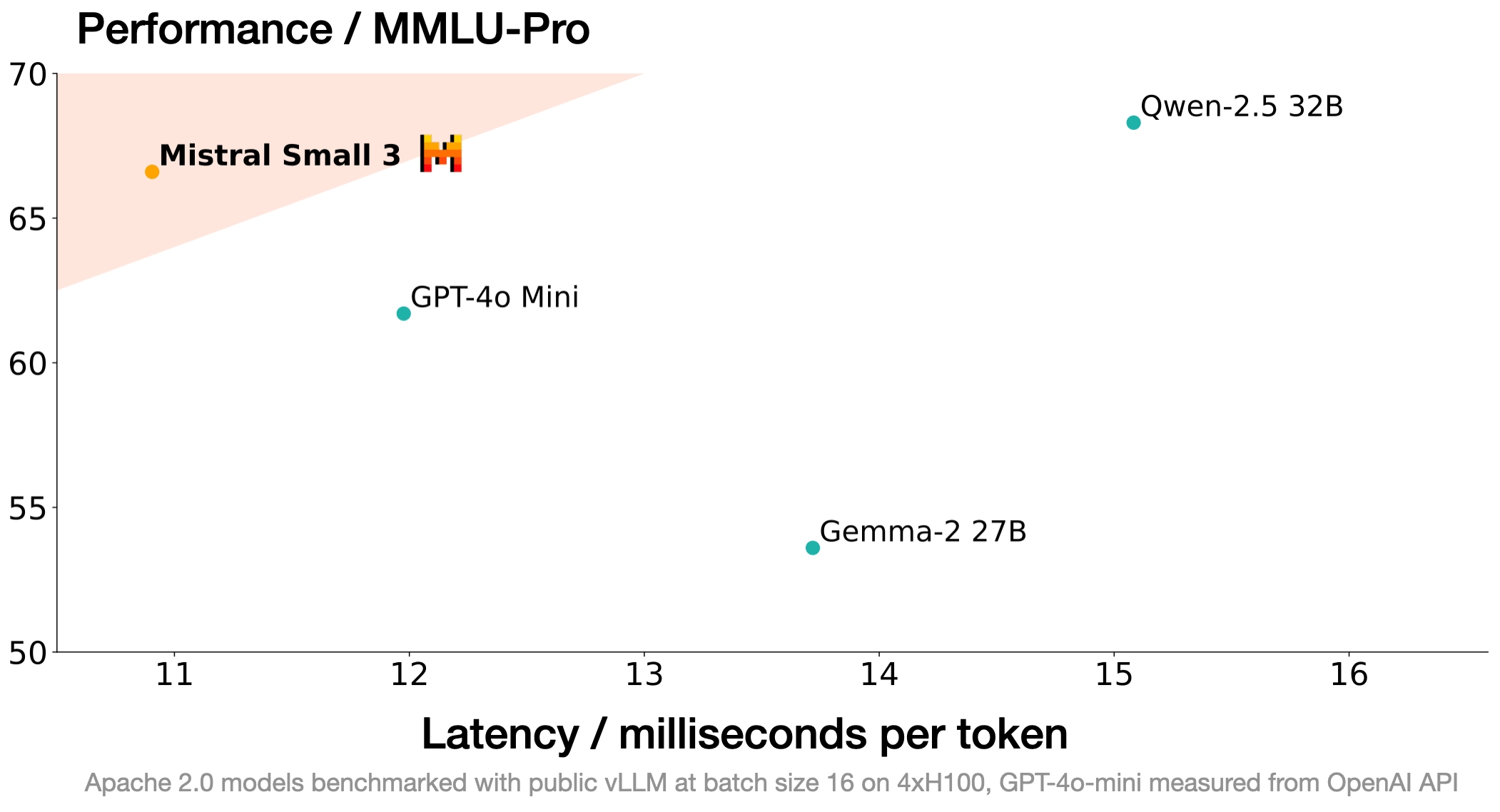
Mistral Small 3 is competitive with larger models such as Llama 3.3 70B or Qwen 32B, and is an excellent open replacement for opaque proprietary models like GPT4o-mini. Mistral Small 3 is on par with Llama 3.3 70B instruct, while being more than 3x faster on the same hardware.
Mistral Small 3 is a pre-trained and instructed model catered to the ‘80%’ of generative AI tasks—those that require robust language and instruction following performance, with very low latency.
We designed this new model to saturate performance at a size suitable for local deployment. Particularly, Mistral Small 3 has far fewer layers than competing models, substantially reducing the time per forward pass. At over 81% accuracy on MMLU and 150 tokens/s latency, Mistral Small is currently the most efficient model of its category.
We’re releasing both a pretrained and instruction-tuned checkpoint under Apache 2.0. The checkpoints can serve as a powerful base for accelerating progress. Note that Mistral Small 3 is neither trained with RL nor synthetic data, so is earlier in the model production pipeline than models like Deepseek R1 (a great and complementary piece of open-source technology!). It can serve as a great base model for building accrued reasoning capacities. We look forward to seeing how the open-source community adopts and customizes it.
Performance
Human Evaluations
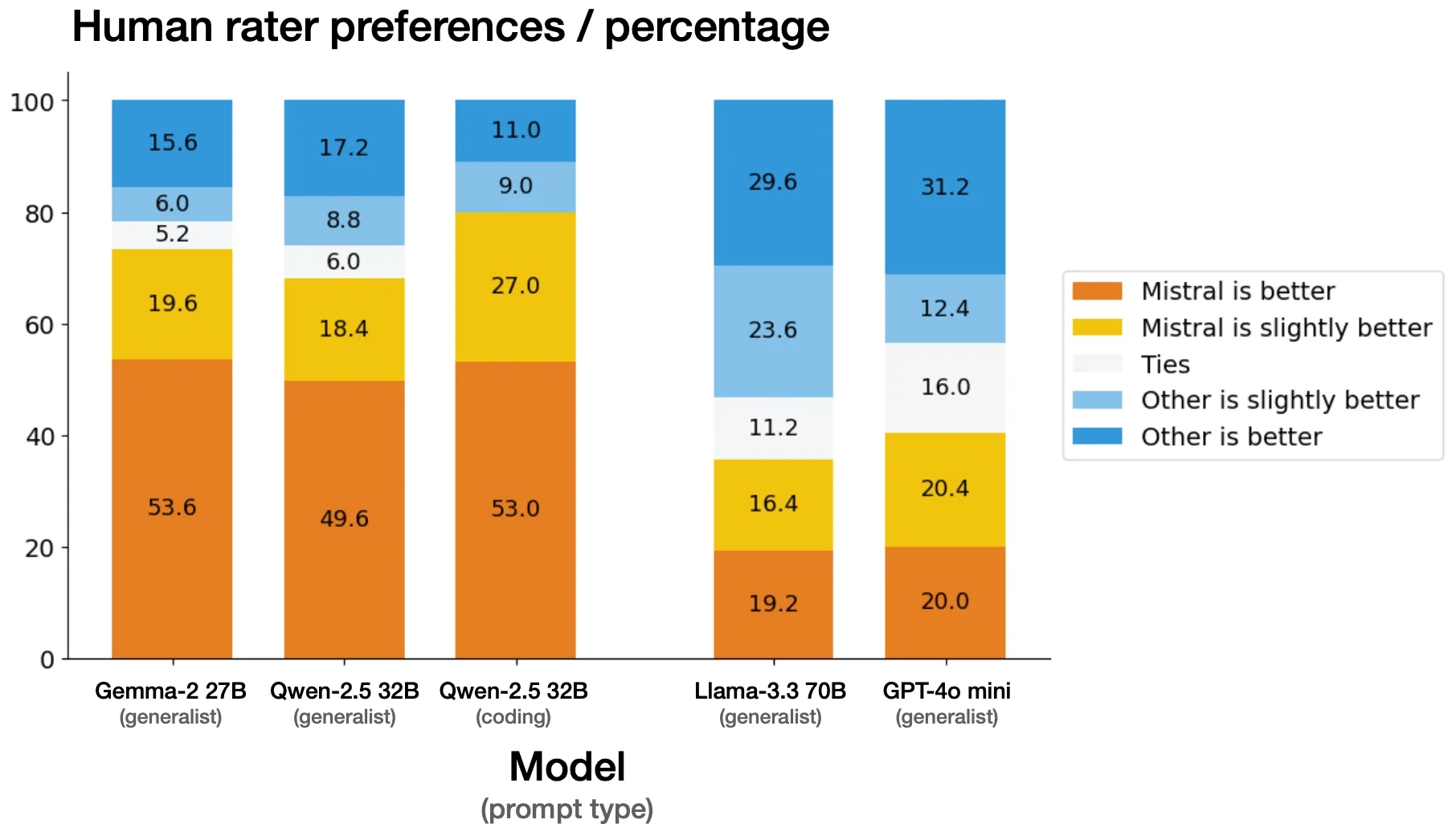
We conducted side by side evaluations with an external third-party vendor, on a set of over 1k proprietary coding and generalist prompts. Evaluators were tasked with selecting their preferred model response from anonymized generations produced by Mistral Small 3 vs another model. We are aware that in some cases the benchmarks on human judgement starkly differ from publicly available benchmarks, but have taken extra caution in verifying a fair evaluation. We are confident that the above benchmarks are valid.
Instruct performance
Our instruction tuned model performs competitively with open weight models three times its size and with proprietary GPT4o-mini model across Code, Math, General knowledge and Instruction following benchmarks.
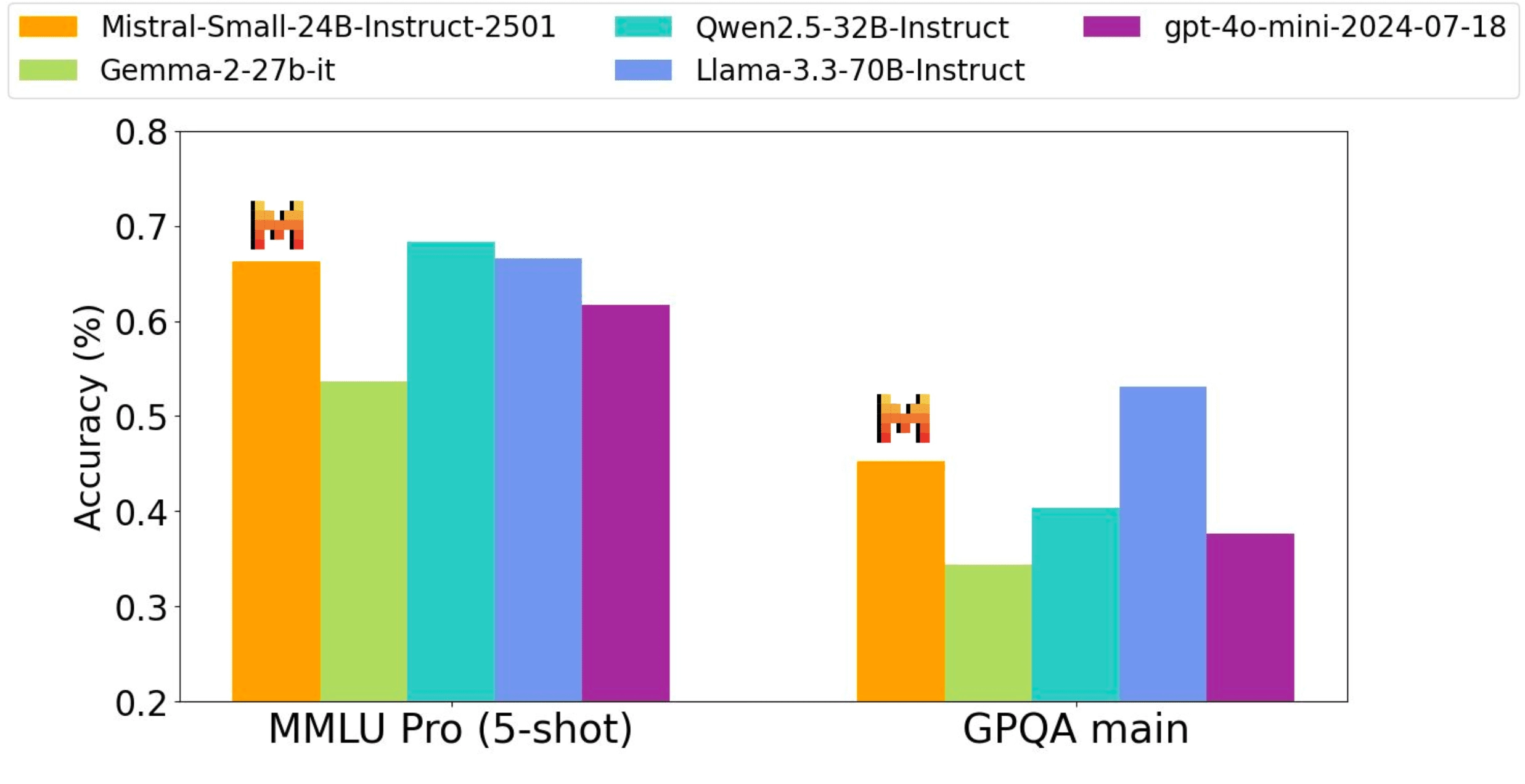
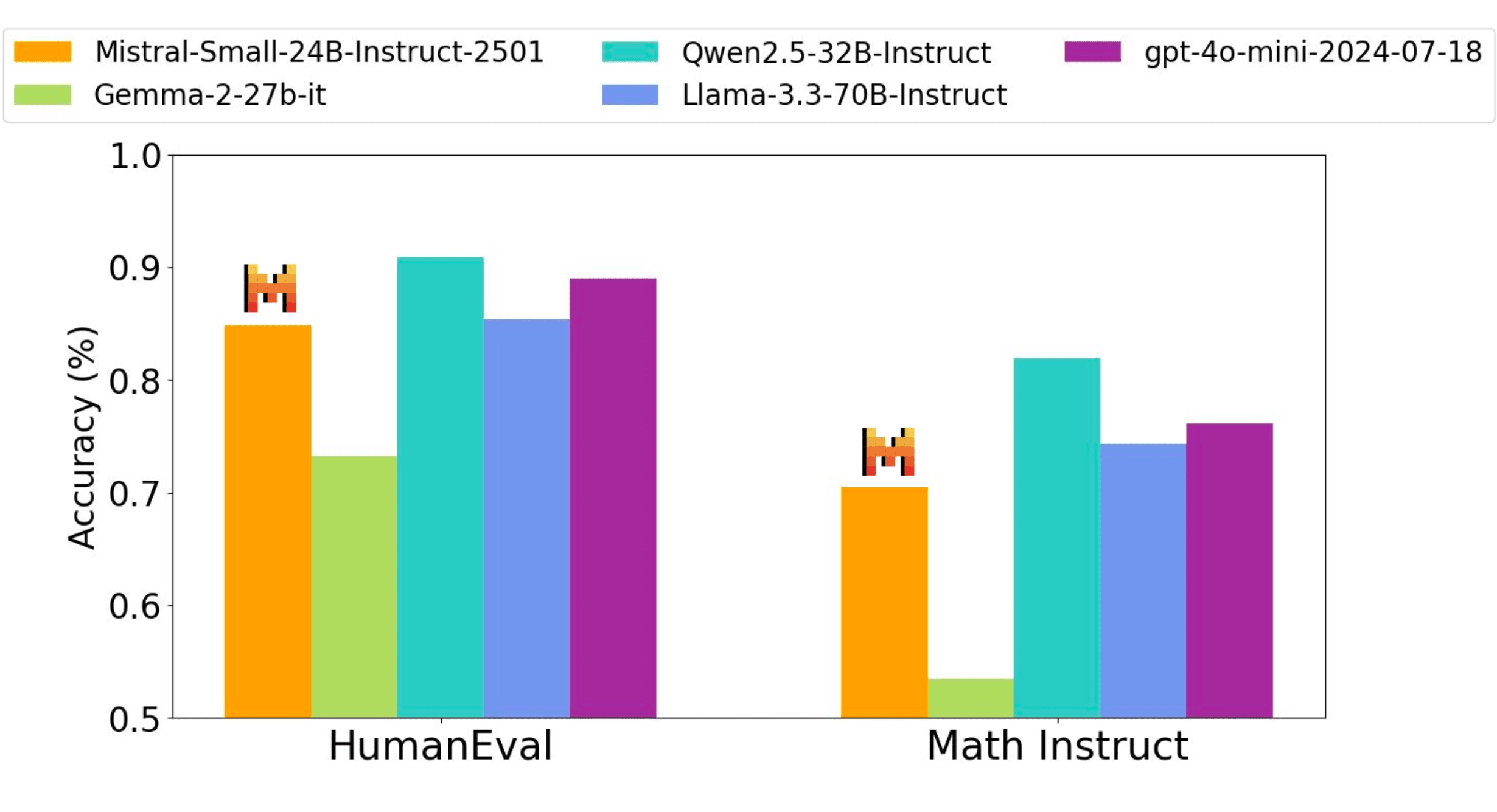
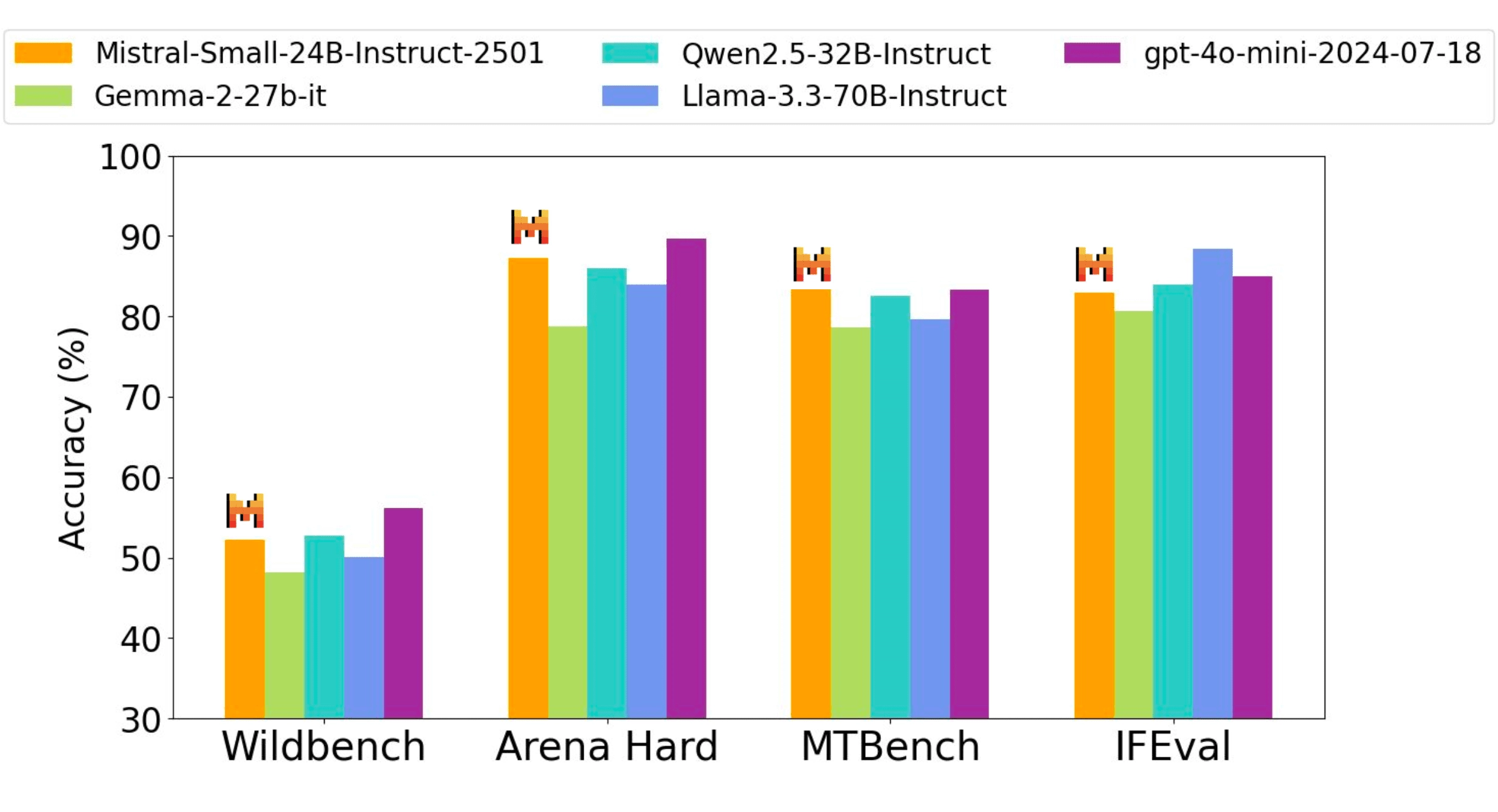
Performance accuracy on all benchmarks were obtained through the same internal evaluation pipeline - as such, numbers may vary slightly from previously reported performance (Qwen2.5-32B-Instruct, Llama-3.3-70B-Instruct, Gemma-2-27B-IT). Judge based evals such as Wildbench, Arena hard and MTBench were based on gpt-4o-2024-05-13.
Pretraining performance
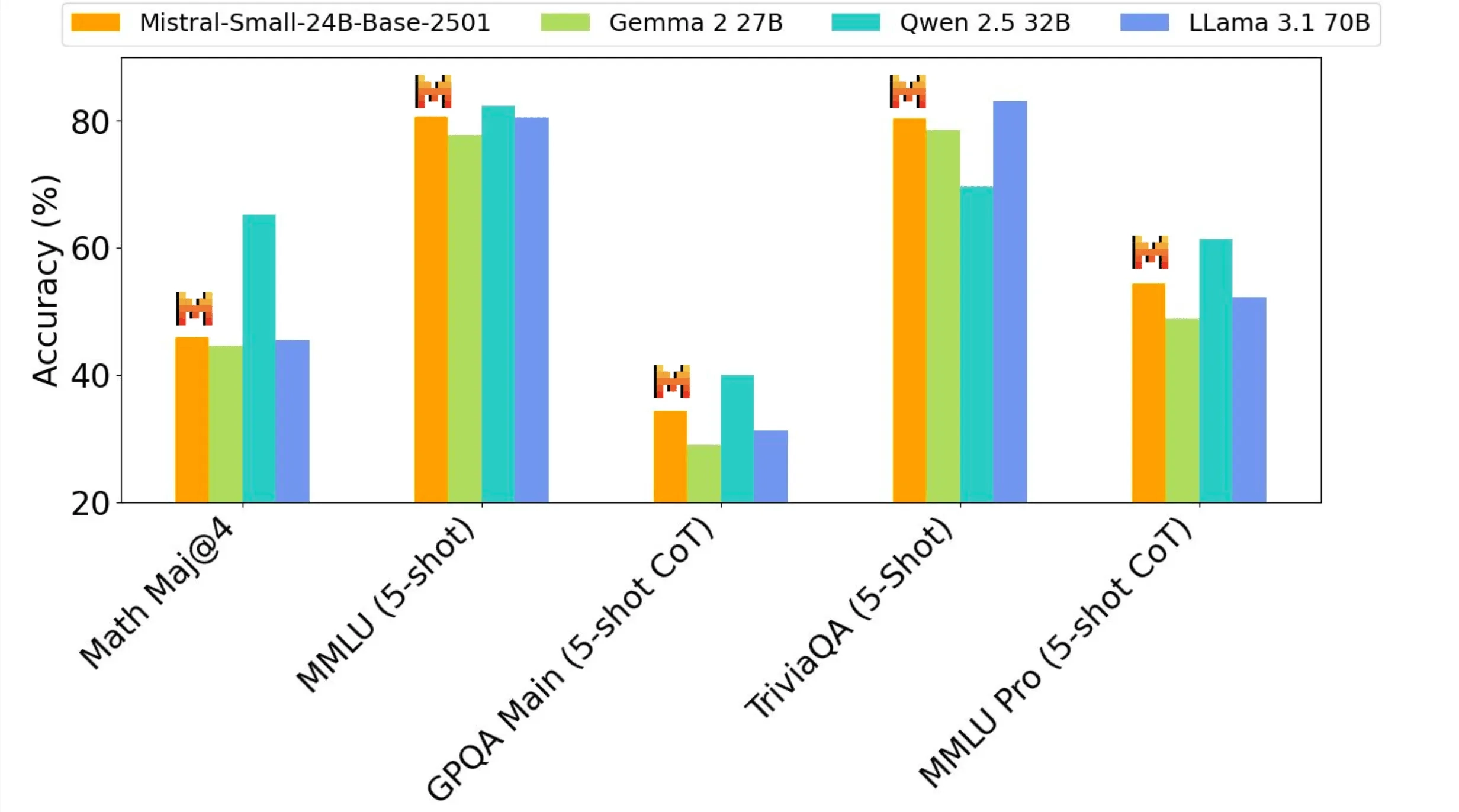
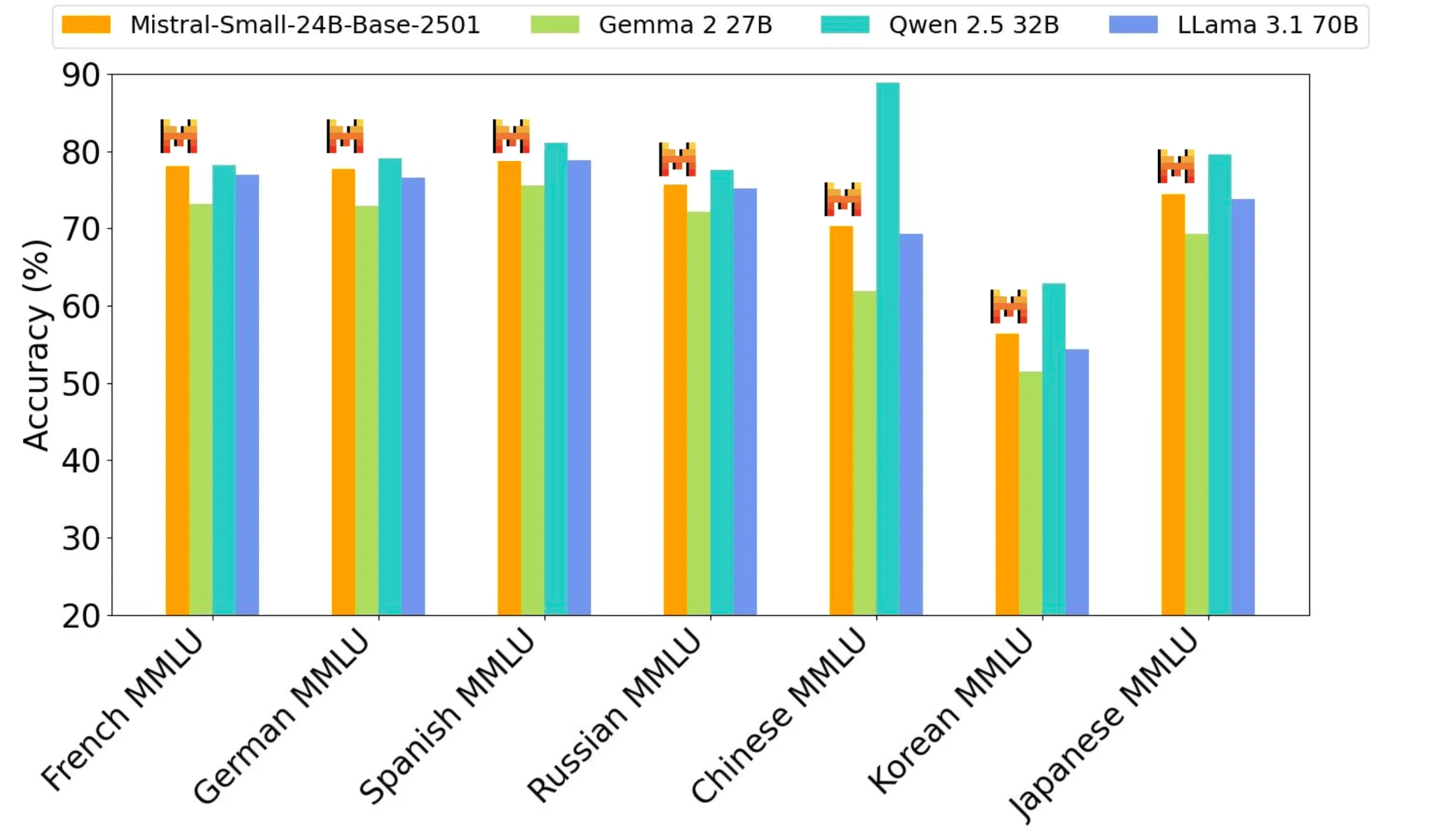
Mistral Small 3, a 24B model, offers the best performance for its size class and rivals with models three times larger such as Llama 3.3 70B.
When to use Mistral Small 3
Across our customers and community, we are seeing several distinct use cases emerge for pre-trained models of this size:
Fast-response conversational assistance: Mistral Small 3 excels in scenarios where quick, accurate responses are critical. This includes virtual assistants in many scenarios where users expect immediate feedback and near real-time interactions.
Low-latency function calling: Mistral Small 3 is able to handle rapid function execution when used as part of automated or agentic workflows.
Fine-tuning to create subject matter experts: Mistral Small 3 can be fine-tuned to specialize in specific domains, creating highly accurate subject matter experts. This is particularly useful in fields like legal advice, medical diagnostics, and technical support, where domain-specific knowledge is essential.
Local inference: Particularly beneficial for hobbyists and organizations handling sensitive or proprietary information. When quantized, Mistral Small 3 can be run privately on a single RTX 4090 or a Macbook with 32GB RAM.
Our customers are evaluating Mistral Small 3 across multiple industries, including:
Financial services customers for fraud detection
Healthcare providers for customer triaging
Robotics, automotive, and manufacturing companies for on-device command and control
Horizontal use cases across customers include virtual customer service, and sentiment and feedback analysis.
Using Mistral Small 3 on your preferred tech stack
Mistral Small 3 is now available on la Plateforme as mistral-small-latest or mistral-small-2501. Explore our docs to learn how to use our models for text generation.
We are also excited to collaborate with Hugging Face, Ollama, Kaggle, Together AI, and Fireworks AI to make the model available on their platforms starting today:
Coming soon on NVIDIA NIM, Amazon SageMaker, Groq, Databricks and Snowflake
The road ahead
It’s been exciting days for the open-source community! Mistral Small 3 complements large open-source reasoning models like the recent releases of DeepSeek, and can serve as a strong base model for making reasoning capabilities emerge.
Among many other things, expect small and large Mistral models with boosted reasoning capabilities in the coming weeks. Join the journey if you’re keen (we’re hiring), or beat us to it by hacking Mistral Small 3 today and making it better!
Open-source models at Mistral
We’re renewing our commitment to using Apache 2.0 license for our general purpose models, as we progressively move away from MRL-licensed models. As with Mistral Small 3, model weights will be available to download and deploy locally, and free to modify and use in any capacity. These models will also be made available through a serverless API on la Plateforme, through our on-prem and VPC deployments, customisation and orchestration platform, and through our inference and cloud partners. Enterprises and developers that need specialized capabilities (increased speed and context, domain specific knowledge, task-specific models like code completion) can count on additional commercial models complementing what we contribute to the community.