Products
Studio
Créez votre propre univers avec Studio.
Operationalize AI. From frontier<br> models to real-world systems.
Workflows

Connectors

Audio

Agents

OCR

Models



Construire.
Connectez vos sources de données. Organisez votre logique métier. Déployez une IA qui a fait ses preuves en conditions réelles.
Les flux de travail.
Organisez des processus autonomes qui conservent l'état, réessayent en cas d'échec et reprennent automatiquement.
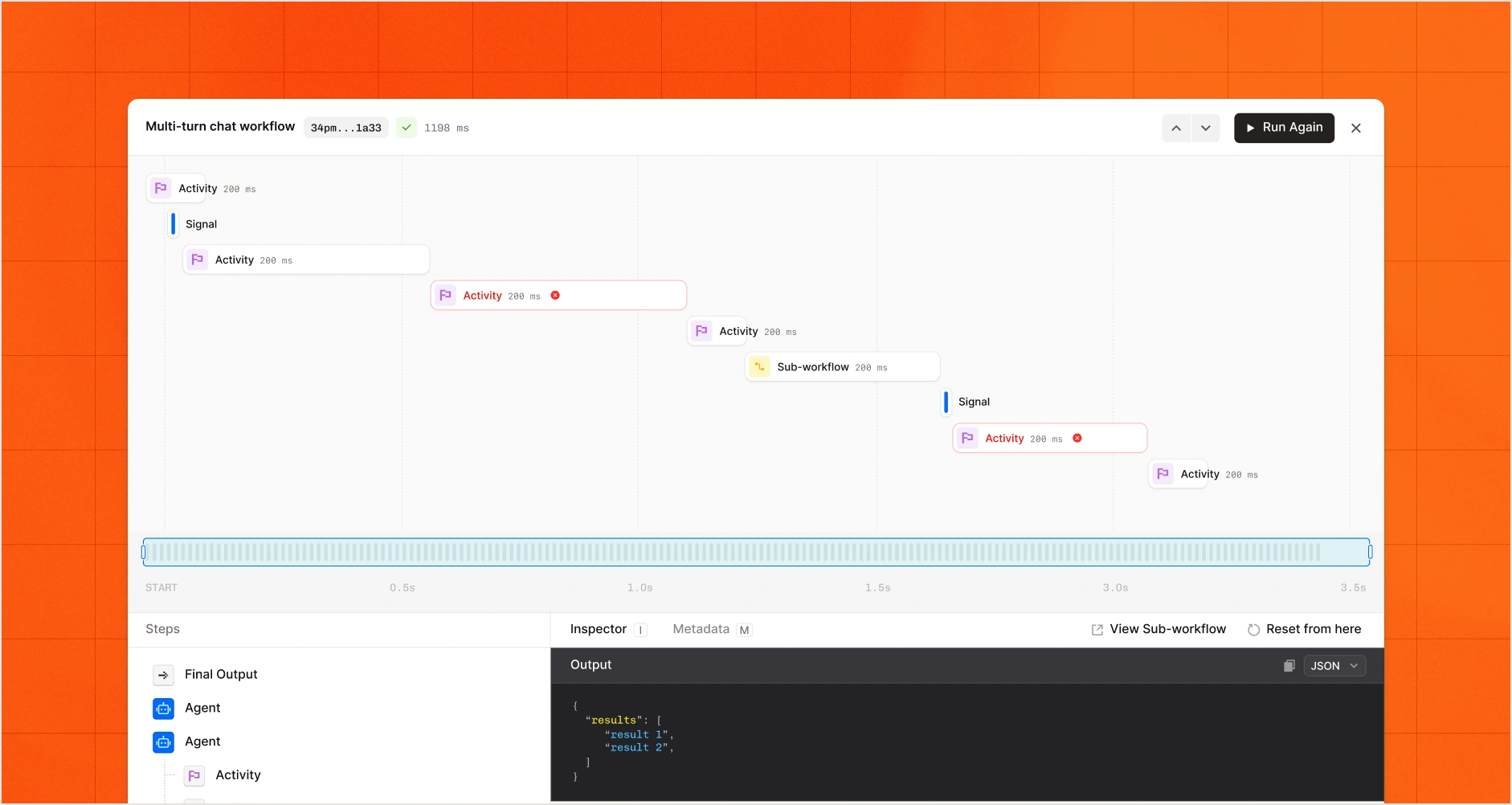
Les agents.
Concevez des agents IA capables de raisonner à travers des outils, des données et des systèmes. Définissez les instructions et le comportement de contrôle avant d'atteindre la phase de production.
Les connecteurs.
Connectez-vous à n'importe quelle source de données d'entreprise grâce à des connecteurs intégrés ou personnalisés. Créez une seule fois et réutilisez sur tous les agents et flux de travail.
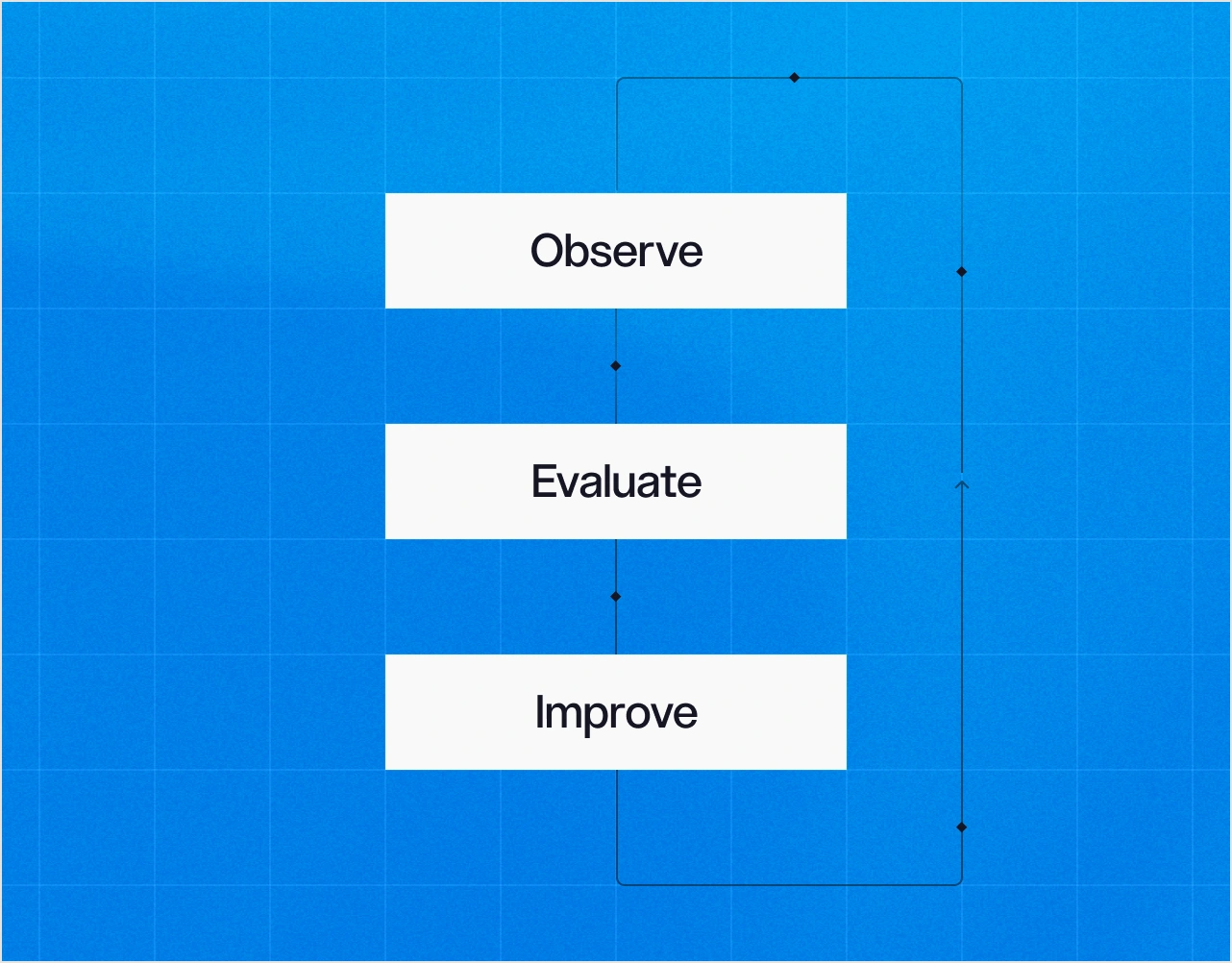
Itérer.
Mesurez ce que votre IA fait réellement. Puis, améliorez-la.
Les essais.
Concevez et comparez les variations de modèles dans des environnements contrôlés. Testez les modifications avant de les mettre à la disposition des utilisateurs.
Les campagnes.
Exécutez des itérations reproductibles et versionnées. Suivez les changements, les améliorations et les dysfonctionnements.
Les juges.
Notez automatiquement les résultats à l'aide de modèles d'évaluation intégrés ou personnalisés. Remplacez l'évaluation subjective par des indicateurs cohérents et exploitables.
Les ensembles de données.
Transformez les données réelles de trafic et les retours en données d'entraînement soigneusement sélectionnées. Chaque interaction devient une opportunité d'amélioration.
Déployer.
Depuis n'importe où. Votre infrastructure, vos règles.
En environnement hybride.
Déployez vos solutions dans des environnements cloud et sur site en toute homogénéité. Une base de code, n'importe quelle infrastructure.
En environnement dédié.
Isolez les charges de travail à des fins de sécurité, de conformité ou de performances. Environnements séparés, aucune ressource partagée.
En environnement auto-hébergé.
Conservez un contrôle total sur l'infrastructure et la résidence des données. Rien ne sort de votre périmètre.
Gérer.
Ne manquez rien. Contrôlez ce qui compte.
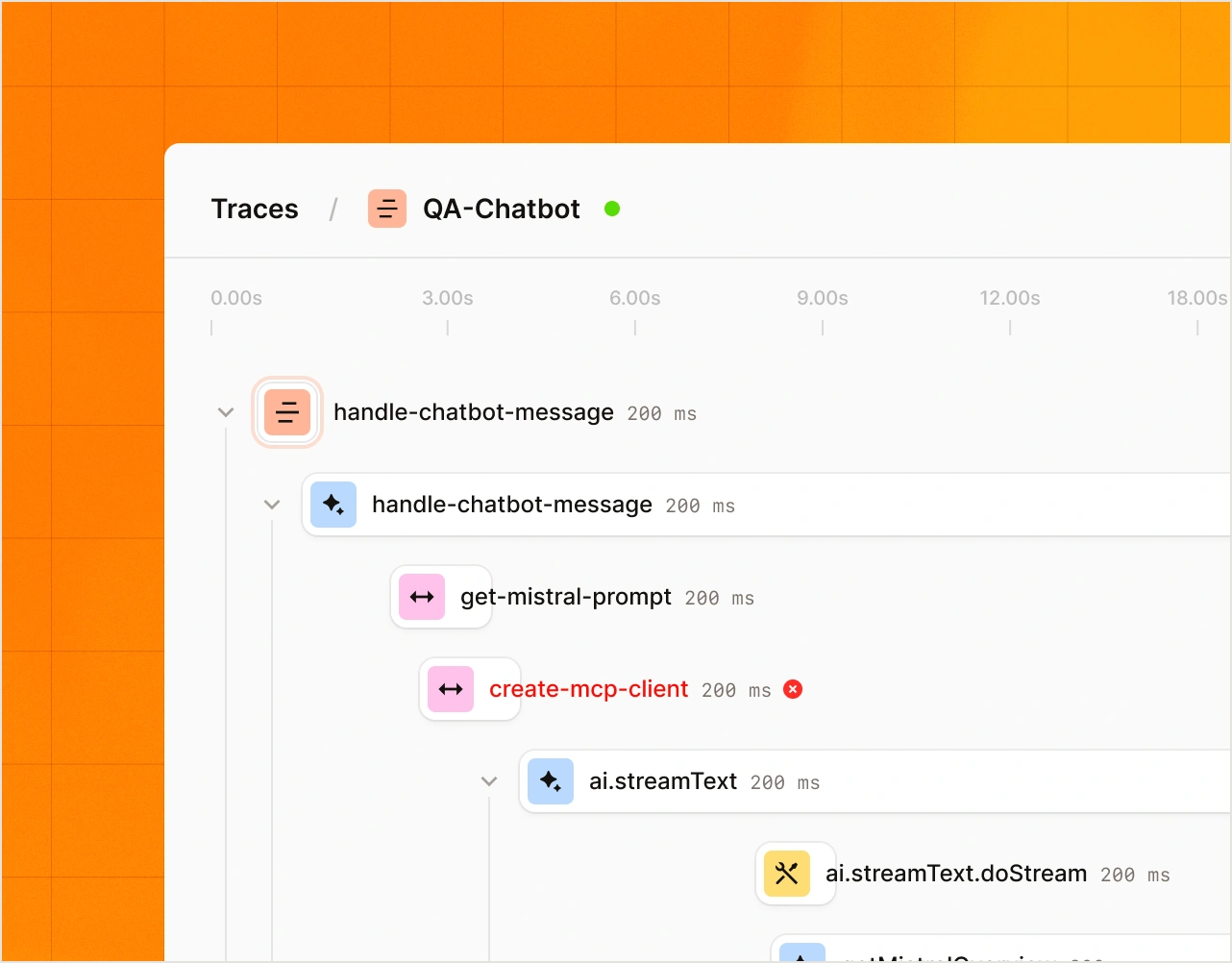
L'observabilité.
Visualisez chaque requête, réponse et décision tout au long des pipelines à plusieurs étapes. Tracés, tableaux de bord et graphiques contextuels en temps réel.
Les mécanismes de contrôle.
Appliquez des contraintes comportementales et de politique lors de l'exécution. Définissez ce que votre IA peut et ne peut pas faire, directement dans le code.

La modération.
Détectez et filtrez automatiquement les sorties à risque ou non conformes. Les règles s'appliquent à chaque réponse, et non pas par après.

Accélérer.
Le premier cas d'utilisation de l'IA peut prendre du temps. Cela ne doit pas être le cas pour les 10 prochaines.
AI registry.
A unified catalog for models, agents, prompts, skills, datasets, and workflows. Full lineage and access controls, all in one place.

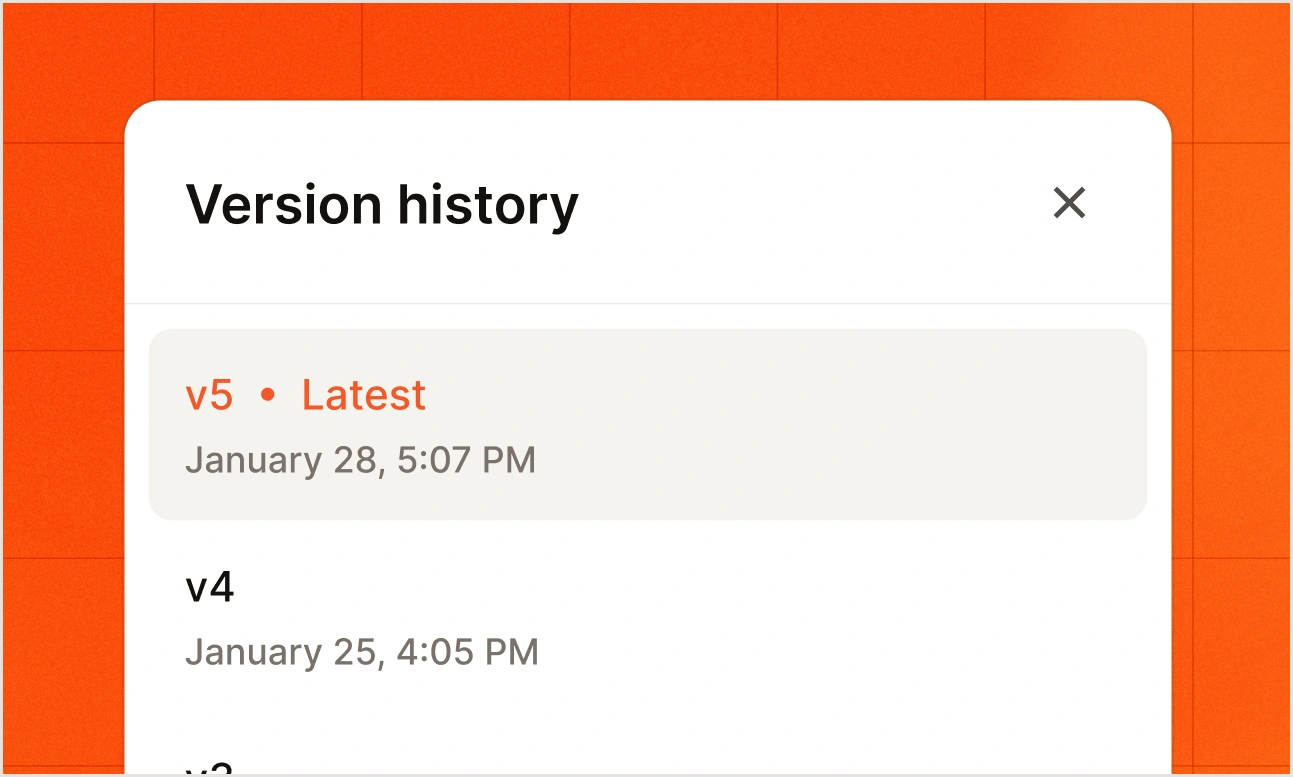
La gestion des versions et de la traçabilité.
Suivez chaque changement au sein des équipes. Réutilisez vos ressources en toute confiance. Revenez en arrière instantanément si nécessaire.
La boîte à outils pour les développeurs.
API, SDK, exemples de code et composants prédéfinis. Tout ce dont vous avez besoin pour commencer à développer en quelques minutes, et non en plusieurs semaines.

Construisez l'avenir.