- December 11, 2023
- Mistral AI team
Mistral AI brings the strongest open generative models to the developers, along with efficient ways to deploy and customise them for production.
We’re opening a beta access to our first platform services today. We start simple: la plateforme serves three chat endpoints for generating text following textual instructions and an embedding endpoint. Each endpoint has a different performance/price tradeoff.
Generative endpoints
The two first endpoints, mistral-tiny and mistral-small, currently use our two released open models; the third, mistral-medium, uses a prototype model with higher performances that we are testing in a deployed setting.
We serve instructed versions of our models. We have worked on consolidating the most effective alignment techniques (efficient fine-tuning, direct preference optimisation) to create easy-to-control and pleasant-to-use models. We pre-train models on data extracted from the open Web and perform instruction fine-tuning from annotations.
Mistral-tiny. Our most cost-effective endpoint currently serves Mistral 7B Instruct v0.2, a new minor release of Mistral 7B Instruct. Mistral-tiny only works in English. It obtains 7.6 on MT-Bench. The instructed model can be downloaded here.
Mistral-small. This endpoint currently serves our newest model, Mixtral 8x7B, described in more detail in our blog post. It masters English/French/Italian/German/Spanish and code and obtains 8.3 on MT-Bench.
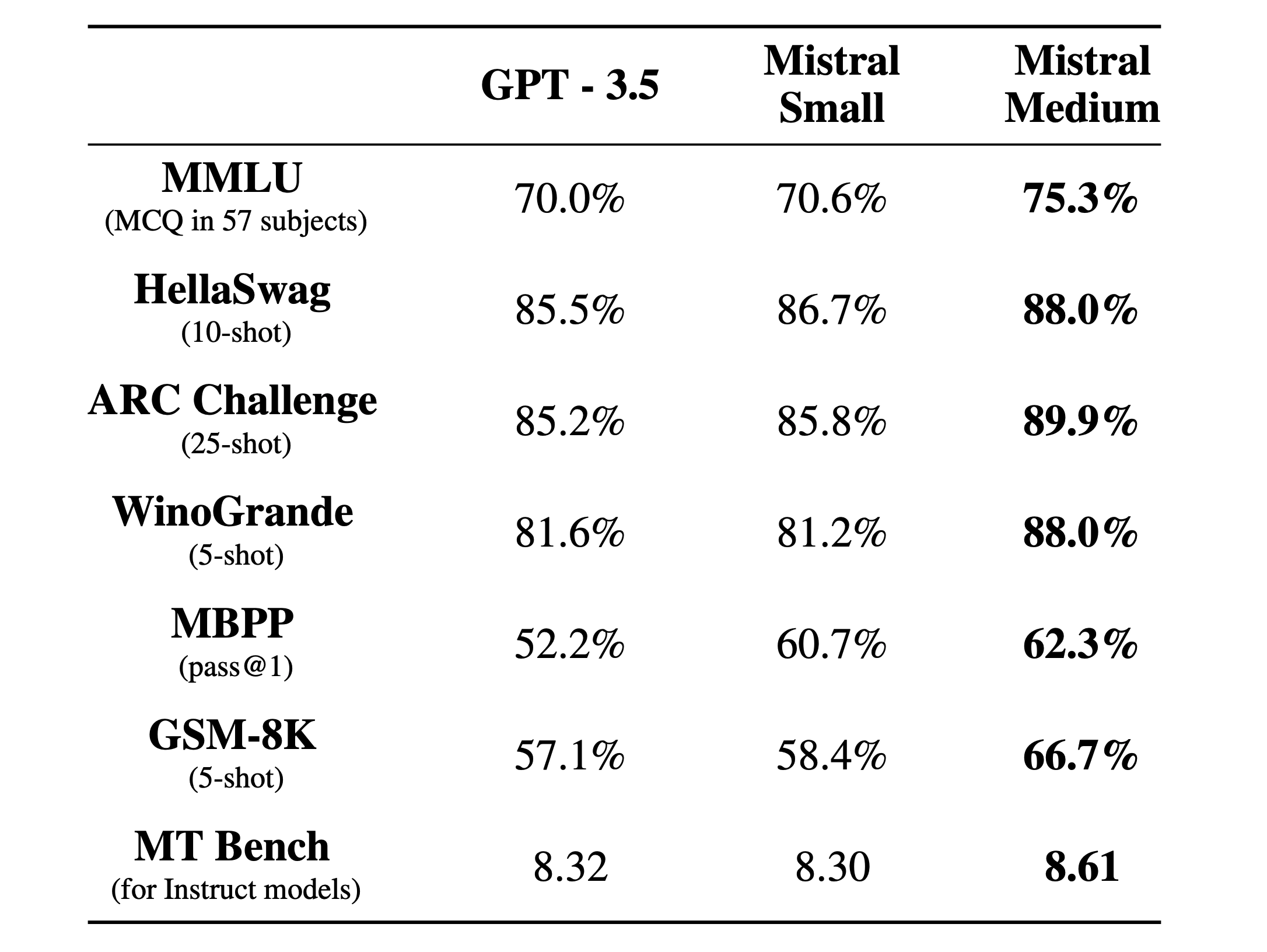
Mistral-medium. Our highest-quality endpoint currently serves a prototype model, that is currently among the top serviced models available based on standard benchmarks. It masters English/French/Italian/German/Spanish and code and obtains a score of 8.6 on MT-Bench. The following table compare the performance of the base models of Mistral-medium, Mistral-small and the endpoint of a competitor.
Embedding endpoint
Mistral-embed, our embedding endpoint, serves an embedding model with a 1024 embedding dimension. Our embedding model has been designed with retrieval capabilities in mind. It achieves a retrieval score of 55.26 on MTEB.
API specifications
Our API follows the specifications of the popular chat interface initially proposed by our dearest competitor. We provide a Python and Javascript client library to query our endpoints. Our endpoints allow users to provide a system prompt to set a higher level of moderation on model outputs for applications where this is an important requirement.
Ramping up from beta access to general availability
Anyone can register to use our API as of today as we progressively ramp up our capacity. Our business team can help qualify your needs and accelerate access. Expect rough edges as we stabilise our platform towards fully self-served availability.
Acknowledgement
We are grateful to NVIDIA for supporting us in integrating TensorRT-LLM and Triton and working alongside us to make a sparse mixture of experts compatible with TRT-LLM.