



Large Language Models (LLMs) are rapidly becoming essential tools for creating widely-used applications. But making sure these models perform as expected is much easier said than done. Evaluating LLM systems isn't just about verifying the outputs are coherent, but also about making sure the answers are relevant and meet the necessary requirements.
The Rise of RAG Systems
Retrieval-Augmented Generation (RAG) systems have become a popular way to boost LLM capabilities. By pairing an LLM with a data retrieval system, LLMs can generate responses that are not only coherent but also grounded in relevant and current information. This helps cut down on moments when the model sounds confident but may actually be hallucinating.
However, evaluating whether these RAG systems are performant isn't straightforward. It's not just about whether the output generated by the LLMs sounds correct, it's also about verifying at the source if the retrieved information is relevant and accurate. Traditional methods often miss these nuances, making a comprehensive evaluation framework essential.
Taking a step back, there are many domains that face this same problem where there may be a lack of clear quantitative metrics or evaluation data to measure performance against and the measures of success may be more qualitative and nuanced.
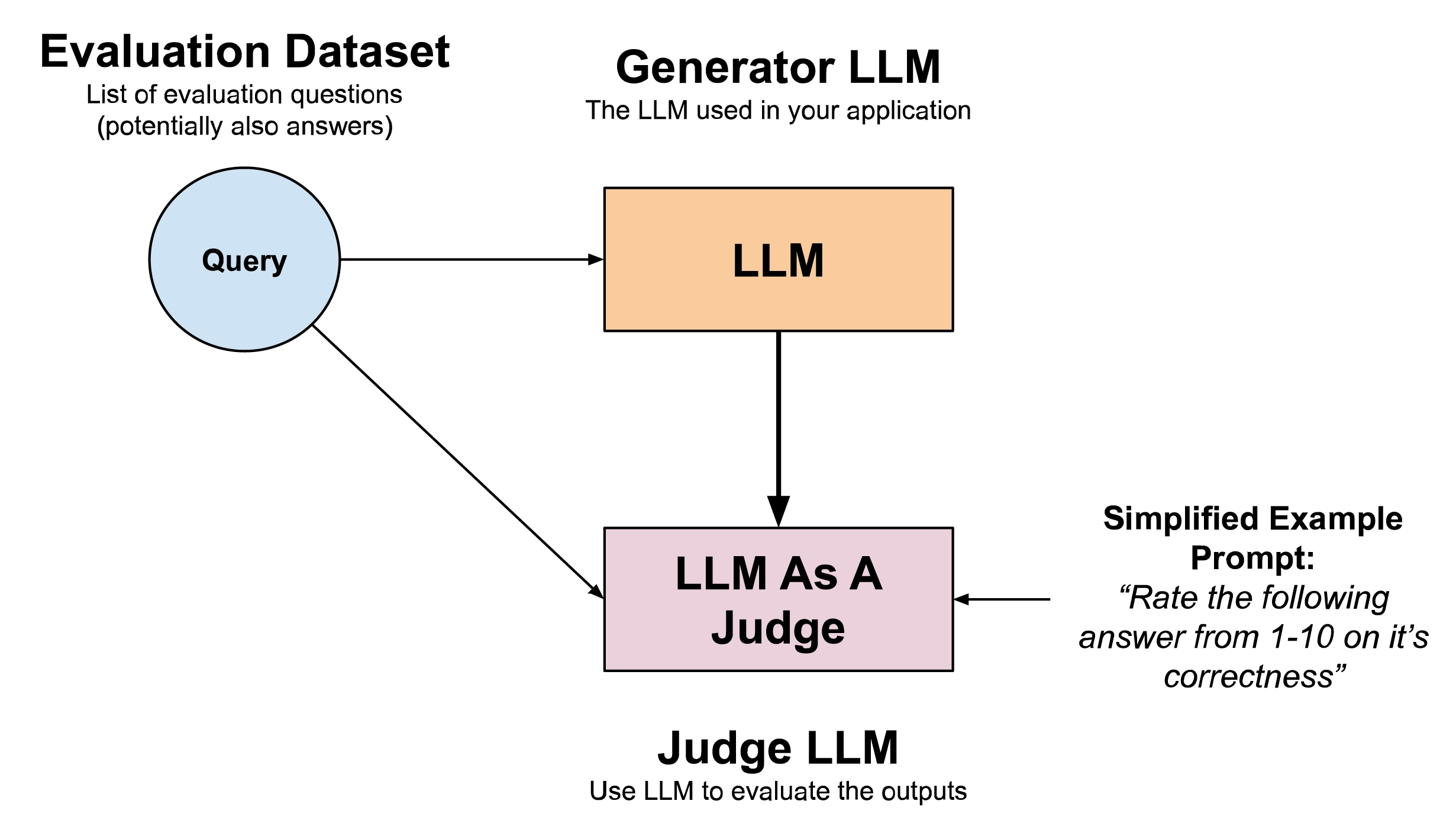
LLM As A Judge: Using LLMs to Evaluate Other LLMs
In scenarios in which evaluations must be run at scale and there is a lack of human evaluators, “LLM As A Judge” has become a popular solution to evaluate the answers of LLM systems.
The way an “LLM As A Judge” typically works is to create a “judge LLM” that given the answer of a “generator LLM” is instructed to grade that answer based on a given scale. This scale can be numerical (e.g a 1-10 or 0-3 scale), binary (e.g True or False) or qualitative (e.g “Excellent”, “Good”, “Okay”, “Bad”). This grade can then be averaged across all questions of an evaluation dataset for an overall weighted score.
For the instruction prompt of an “LLM as A Judge” you can create custom criteria for the LLM to evaluate answers on. For example you can create specific grading criteria checking if responses are accurate, relevant, and grounded. Mistral’s models can be effectively used for both the generator and judge component of LLM systems.
The RAG Triad: A More Holistic Evaluation Framework
The RAG Triad is a popular evaluation framework for evaluating RAG systems designed to check the reliability and contextual integrity of LLM responses from the data sources. It was introduced by TruLens and several similar frameworks created like RAGAS have been created in order to more qualitatively evaluate RAG systems.
The RAG Triad focuses on three key areas:
1. Context Relevance: This metric checks if the retrieved documents align well with the user's query. It ensures that the information used to generate the response is relevant and appropriate, setting the stage for a coherent and useful answer.
2. Groundedness: This metric verifies if the generated response is based accurately on the retrieved context. It ensures that the LLM's output is factual and reliable, reducing the risk of those pesky hallucinations.
3. Answer Relevance: This metric assesses how well the final response addresses the user's original query. It ensures that the generated answer is helpful and on point, aligning with the user's intent and providing valuable insights.
By using the RAG Triad, evaluators can get a comprehensive view of the LLM's performance, spot potential issues, and ensure that the responses are accurate, reliable, and contextually sound. This framework helps build trustworthy interactions between humans, AI and knowledge bases.
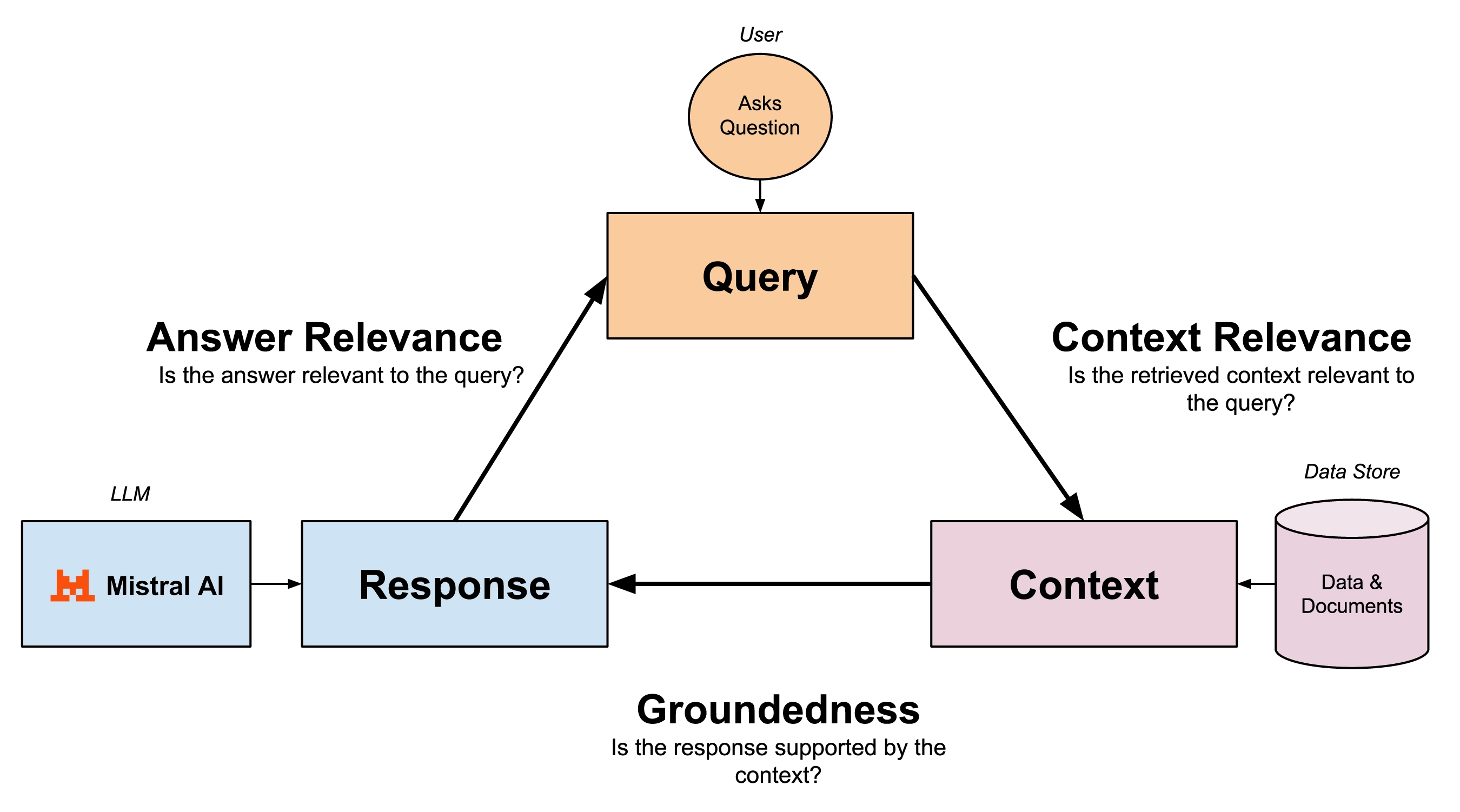
This is particularly useful in evaluating a RAG LLM system end-to-end as it includes assessing both the retrieval and generation steps. This helps evaluate not just the LLM answer, but also it’s correctness relative to the source data retrieved.
Structured Outputs: A Practical Solution
Custom structured outputs is a recent feature launched in our API which allows you to control the output format of LLMs and give values in a structured machine readable way so you have greater reliability.
Mistral's models together with structured outputs offer a practical way to implement the RAG triad and combat common evaluation challenges. By setting a clear criteria and schema for values, structured outputs help you build a more reliable “LLM As A Judge” that can be used for evaluating LLM systems.
Structured outputs sets a perfect framework to define new and reusable criteria and enforce a format that is then easily machine readable for evaluation.
from pydantic import BaseModel, Field
# Assuming Score is defined elsewhere, e.g.:# Score = int | float | Enum # Replace with your actual Score type
SCORE_DESCRIPTION = "A numerical or categorical score representing the evaluation metric."
class ContextRelevance(BaseModel): explanation: str = Field( ..., description=( "Step-by-step reasoning explaining how the retrieved context aligns with the user's query. " "Consider the relevance of the information to the query's intent and the appropriateness of the context " "in providing a coherent and useful response." ) ) score: Score = Field(..., description=SCORE_DESCRIPTION)
class AnswerRelevance(BaseModel): explanation: str = Field( ..., description=( "Step-by-step reasoning explaining how well the generated answer addresses the user's original query. " "Consider the helpfulness and on-point nature of the answer, aligning with the user's intent and providing valuable insights." ) ) score: Score = Field(..., description=SCORE_DESCRIPTION)
class Groundedness(BaseModel): explanation: str = Field( ..., description=( "Step-by-step reasoning explaining how faithful the generated answer is to the retrieved context. " "Consider the factual accuracy and reliability of the answer, ensuring it is grounded in the retrieved information." ) ) score: Score = Field(..., description=SCORE_DESCRIPTION)
class RAGEvaluation(BaseModel): context_relevance: ContextRelevance = Field( ..., description="Evaluation of the context relevance to the query, considering how well the retrieved context aligns with the user's intent." ) answer_relevance: AnswerRelevance = Field( ..., description="Evaluation of the answer relevance to the query, assessing how well the generated answer addresses the user's original query." ) groundedness: Groundedness = Field( ..., description="Evaluation of the groundedness of the generated answer, ensuring it is faithful to the retrieved context." )
Conclusion
Evaluating LLM systems is crucial for developing reliable AI applications. The RAG Triad, along with Mistral's structured outputs, provides a robust framework for assessing LLM performance with LLM as a judge. By focusing on context relevance, groundedness, and answer relevance, we can ensure that LLM responses are more accurate and meaningful. This approach enhances the user experience and the reliability of AI-driven applications, creating a more trustworthy interaction with the AI system.
Full Code
You can find the full code for LLM As A Judge for RAG here:
https://github.com/mistralai/cookbook/blob/main/mistral/evaluation/RAG_evaluation.ipynb
Contact Us
Interested in more custom work with the Mistral AI team? Contact us for solution support