



Mixtral 8x22B is our latest open model. It sets a new standard for performance and efficiency within the AI community. It is a sparse Mixture-of-Experts (SMoE) model that uses only 39B active parameters out of 141B, offering unparalleled cost efficiency for its size.
Mixtral 8x22B comes with the following strengths:
It is fluent in English, French, Italian, German, and Spanish
It has strong mathematics and coding capabilities
It is natively capable of function calling; along with the constrained output mode implemented on la Plateforme, this enables application development and tech stack modernisation at scale
Its 64K tokens context window allows precise information recall from large documents
Truly open
We believe in the power of openness and broad distribution to promote innovation and collaboration in AI.
We are, therefore, releasing Mixtral 8x22B under Apache 2.0, the most permissive open-source licence, allowing anyone to use the model anywhere without restrictions.
Efficiency at its finest
We build models that offer unmatched cost efficiency for their respective sizes, delivering the best performance-to-cost ratio within models provided by the community.
Mixtral 8x22B is a natural continuation of our open model family. Its sparse activation patterns make it faster than any dense 70B model, while being more capable than any other open-weight model (distributed under permissive or restrictive licenses). The base model's availability makes it an excellent basis for fine-tuning use cases.
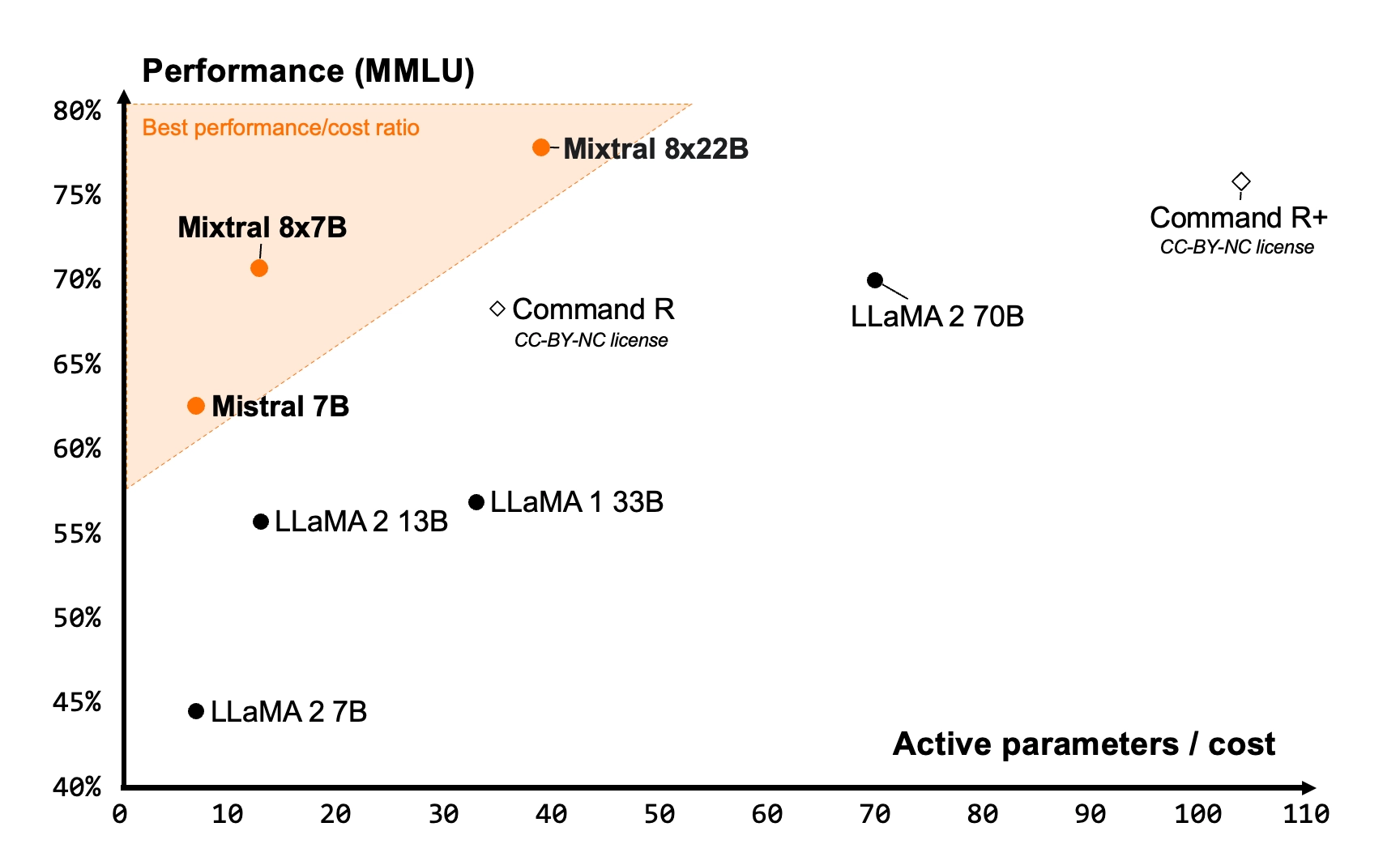
Figure 1: Measure of the performance (MMLU) versus inference budget tradeoff (number of active parameters). Mistral 7B, Mixtral 8x7B and Mixtral 8x22B all belong to a family of highly efficient models compared to the other open models.
Unmatched open performance
The following is a comparison of open models on standard industry benchmarks.
Reasoning and knowledge
Mixtral 8x22B is optimized for reasoning.
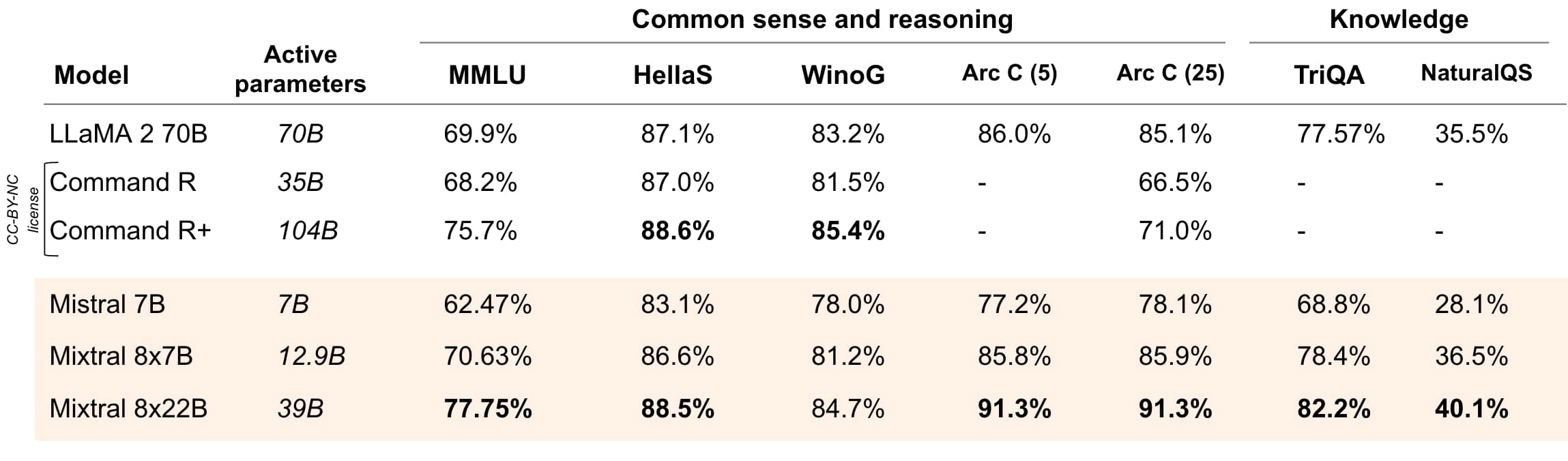
Figure 2: Performance on widespread common sense, reasoning and knowledge benchmarks of the top-leading LLM open models: MMLU (Measuring massive multitask language in understanding), HellaSwag (10-shot), Wino Grande (5-shot), Arc Challenge (5-shot), Arc Challenge (25-shot), TriviaQA (5-shot) and NaturalQS (5-shot).
Multilingual capabilities
Mixtral 8x22B has native multilingual capabilities. It strongly outperforms LLaMA 2 70B on HellaSwag, Arc Challenge and MMLU benchmarks in French, German, Spanish and Italian.
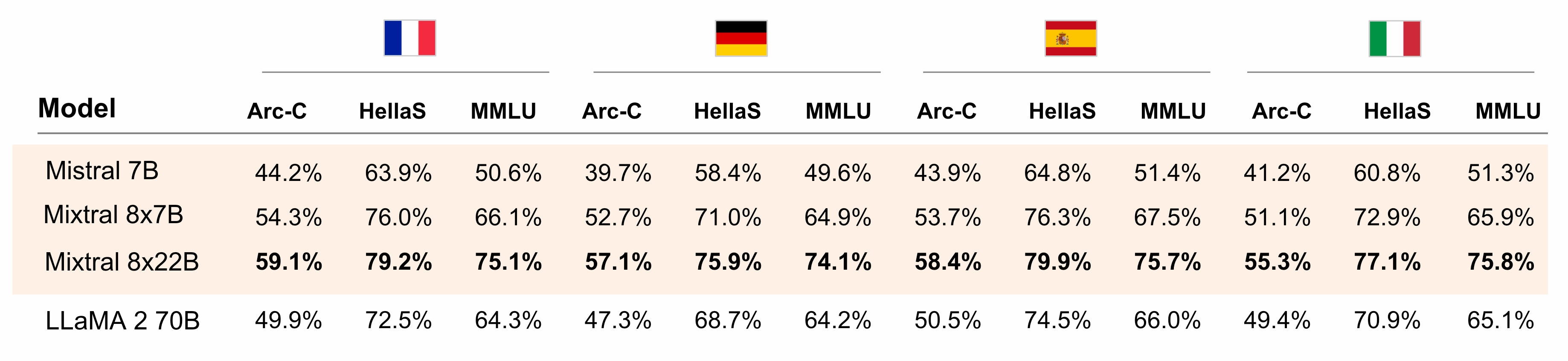
Figure 3: Comparison of Mistral open source models and LLaMA 2 70B on HellaSwag, Arc Challenge and MMLU in French, German, Spanish and Italian.
Maths & Coding
Mixtral 8x22B performs best in coding and maths tasks compared to the other open models.
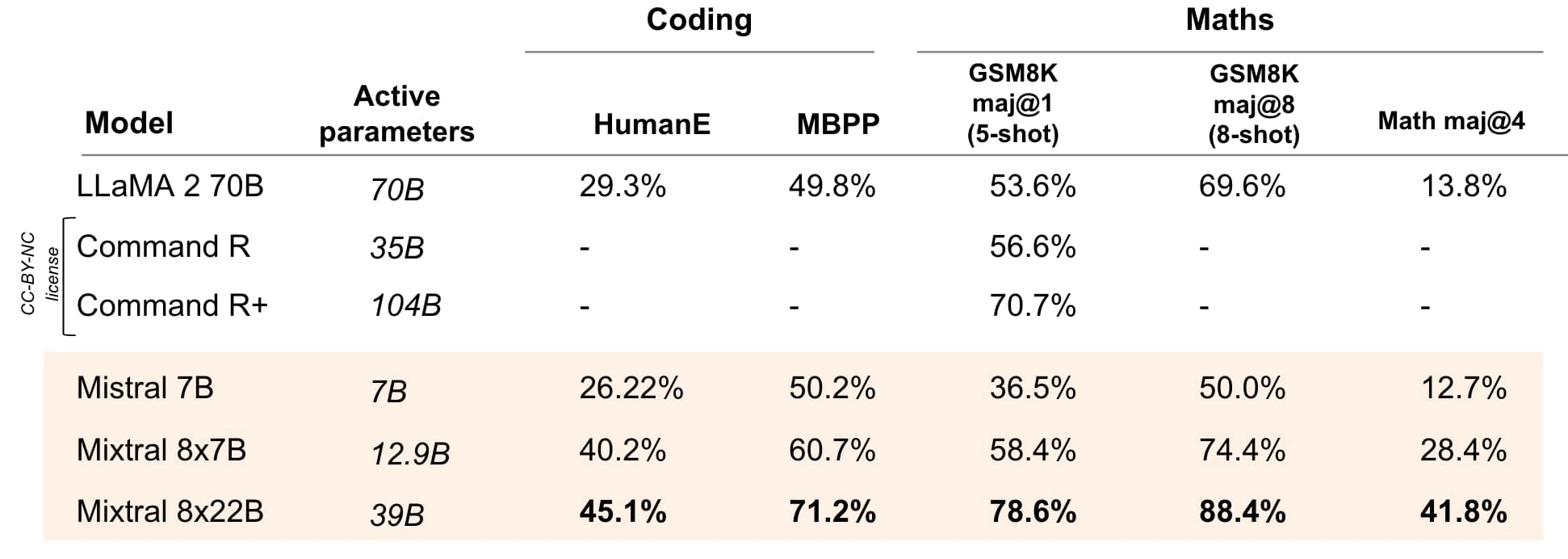
Figure 4: Performance on popular coding and maths benchmarks of the leading open models: HumanEval pass@1, MBPP pass@1, GSM8K maj@1 (5 shot), GSM8K maj@8 (8-shot) and Math maj@4.
The instructed version of the Mixtral 8x22B released today shows even better math performance, with a score of 90.8% on GSM8K maj@8 and a Math maj@4 score of 44.6%.
Explore Mixtral 8x22B now on la Plateforme and join the Mistral community of developers as we define the AI frontier together.