



Fine-tuning foundation models is transforming how we apply AI to real-world problems. By adapting pre-trained models to specific domains, we can unlock dramatically better performance on specialized tasks. Today, we’re excited to share how fine-tuning Pixtral-12B on satellite imagery leads to significant improvements over the base model, showcasing the power of domain-specific adaptation.
LoRA Fine-Tuning can efficiently adapt model weights to specific tasks
Fine-tuning large language models can be resource-intensive, but techniques like Low-Rank Adaptation (LoRA) make it far more efficient. LoRA works by injecting small, trainable rank-decomposition matrices into the model's weights, allowing targeted adaptation without modifying the full model. It enables developers to adapt models to specific tasks, whether it's learning domain-specific vocabulary, adopting a particular tone, or embedding specialized knowledge, without retraining the entire model.
This method shines when prompt engineering or few-shot examples fall short. Complex prompts can become intricate and hard to maintain, often producing inconsistent results. With LoRA-based fine-tuning, a handful of curated examples can steer the model more reliably, achieving better performance with less overhead.
The importance of specialized models to satellite imagery
Satellite imagery is a highly specialized visual domain with critical applications across the global economy. From tracking deforestation and monitoring environmental change to detecting emerging threats, these images power high-stakes decision-making in government, agriculture, defense, and climate science. To extract reliable insights, models must be finely specialized to the unique patterns and semantics of satellite data. This is where fine-tuning Pixtral-12B comes in, bridging the gap between general-purpose vision models and domain-specific expertise.
Case study: classifying satellite images from the Aerial Image Dataset
To demonstrate the impact of fine-tuning, we used the Aerial Image Dataset (AID) introduced by Xia et al under a Public Domain license. This benchmark involves classifying satellite images into detailed scene categories. Many of these classes (such as dense residential vs. medium residential; or ambiguous terms like center) are difficult for general vision-language models to handle without domain-specific context. Fine-tuning provides the model with that context, enabling more accurate and nuanced classification.

Note that smaller, specialized vision models could potentially achieve comparable performance levels. This article aims to guide you through the process of effectively fine-tuning Mistral’s Vision Language Model (VLM) using a straightforward example, and to demonstrate its impact on basic classification metrics. More advanced applications of fine-tuning could include interactions like "speak with an image" or generating image captions.
Pixtral-12B with no finetuning achieves decent results, but falls short on ambiguous classes
We began with a traditional classification setup, splitting the dataset into 8,000 training samples and 2,000 test samples. Using a system prompt that listed all target classes and enforced a structured output format, we achieved reasonable baseline results. However, performance varied significantly across classes, especially those with subtle visual distinctions. Additionally, because the language model isn't explicitly constrained to the label set, it occasionally hallucinated non-existent or invalid class names, highlighting the limitations of purely prompt-based approaches.
Classification system prompt
Classify the following image into the category it belongs to.
- These category labels are Desert; BareLand; RailwayStation; Mountain; Parking; River; Church; MediumResidential; Commercial; Forest; Airport; Bridge; Park; Farmland; SparseResidential; BaseballField; School; Playground; Square; Stadium; Meadow; Beach; Resort; DenseResidential; Port; StorageTanks; Pond; Viaduct; Industrial; Center.
- Output your result using exclusively the following schema: {'image_description': FieldInfo(annotation=str, required=True), 'label': FieldInfo(annotation=str, required=True)}
- Put your results between a json tag
```json ```
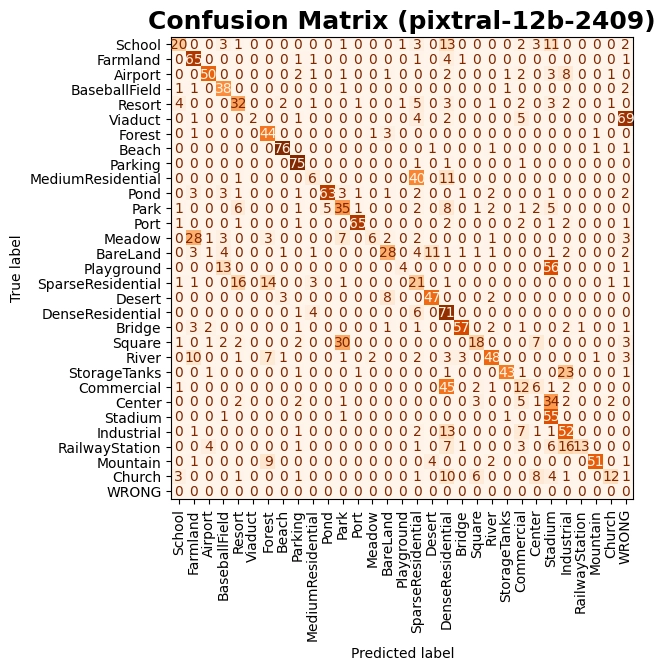
Some classes can be quite challenging to differentiate without prior knowledge or specific criteria. For example, consider the images below showing a "Playground" on the left and a "Stadium" on the right. The base Pixtral model classifies both as "Stadium." Upon closer inspection, the main difference is the presence of seats surrounding the sports field. We anticipate that fine-tuning will help capture these nuances.

Finetuning Mistral model is easy as ABC with our API & LaPlateforme UI
To improve these results, we fine-tuned Pixtral-12B using Mistral’s fine-tuning API. The fine-tuning strategy consisted in providing the "assistant response" with the right label for a system prompt and input image. No extensive hyperparameter tuning was needed here, making the process efficient and cost-effective.
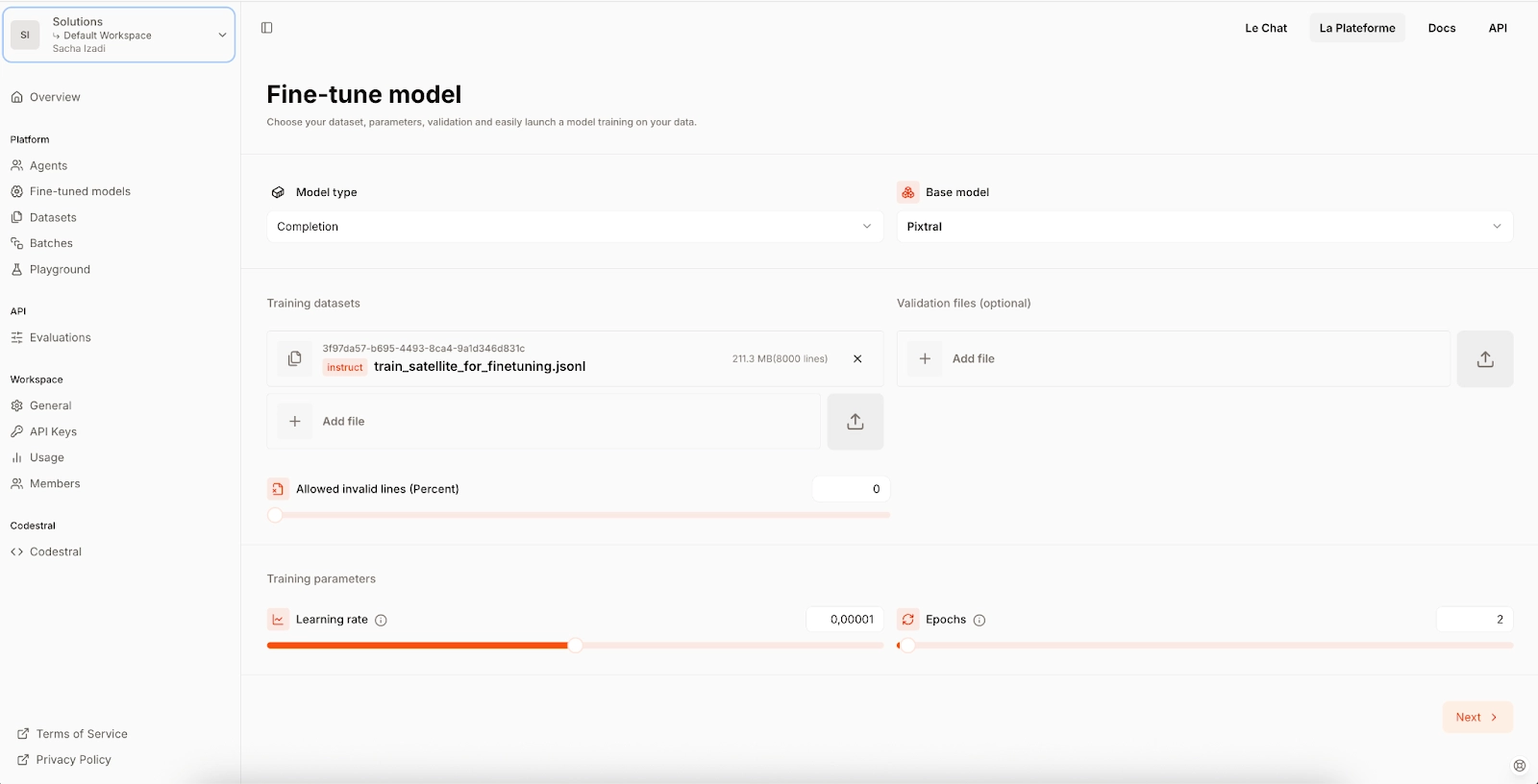
Another option is to launch fine-tuning jobs via LaPlateforme UI
Selecting Hyperparameters
Choosing the right hyperparameters is crucial for successful fine-tuning. Here are some tips:
Learning rate: Start with a small learning rate to avoid overshooting the optimal weights.
Batch size: Use a batch size that fits within your computational resources while providing stable gradients.
Epochs: Begin with a single epoch and monitor performance. Additional epochs can be added if necessary but we recommend to keep a close eye on overfitting risk.
Note: Direct API calls with Mistral fine-tuning API give you more control on the hyperparameters. On LaPlateforme you just need to provide the desired learning rate and number of epochs, the finetuning engine will then compute the optimal batch size based on your dataset size and internal benchmarks of optimal number of tokens per batch.
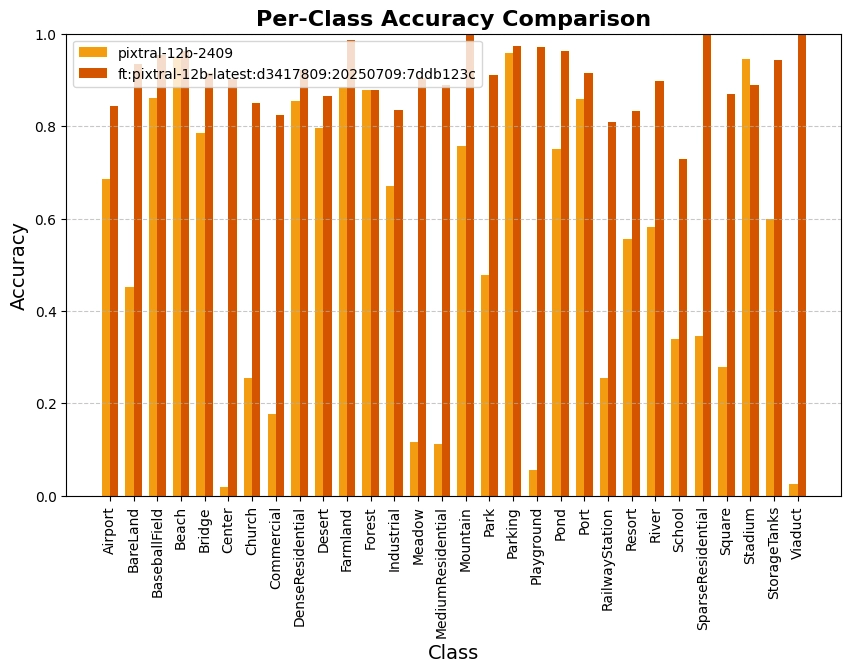
Finetuning help boost model performance by x1.6
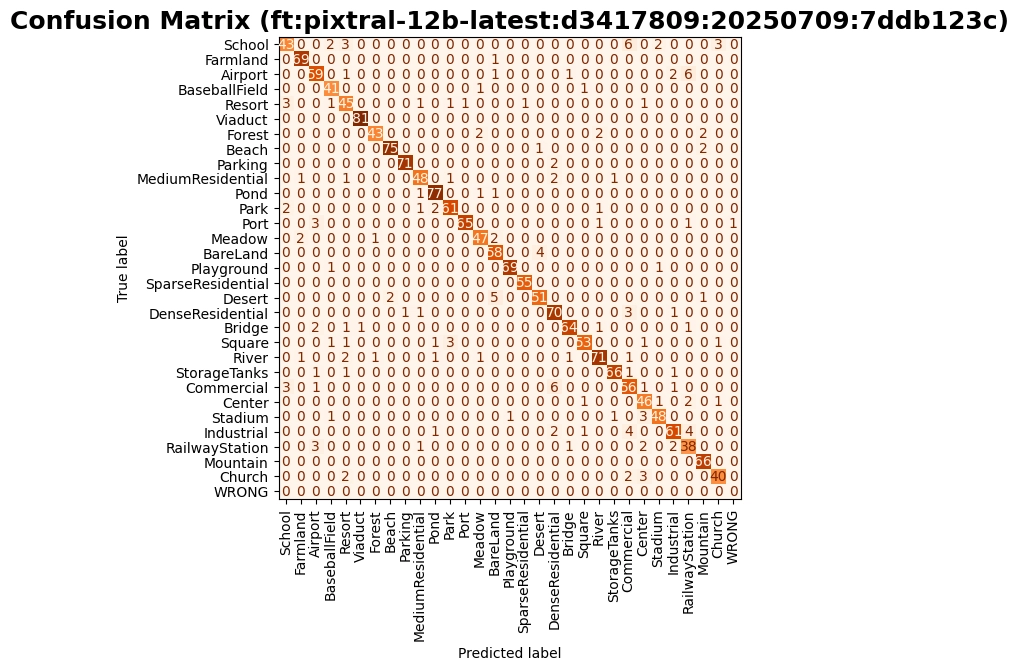
After fine-tuning, we observed a quantum leap in classification metrics for all classes (e.g. overall accuracy increased from 0.56 to 0.91). The model's performance became more consistent across classes, and hallucinations were significantly reduced (from 5% to 0.1%). While the results are not 100% perfect, the improvement was substantial, especially considering the limited budget (≤10$) and the relatively small number of samples (8,000 distributed over 30 classes).
Conclusion
Fine-tuning Pixtral-12B on satellite imagery demonstrates the effectiveness of techniques like LoRA to achieve remarkable improvements in model performance. This approach is not only cost-effective but also scalable, making it ideal for a wide range of applications. Typical examples include highly specialized data, often proprietary, that are underrepresented in traditional VLMs training sets. These can include: medical image captioning, detailed reports from surveillance images, transcription of ancient manuscripts, etc.
For more details on the implementation, have a look at our cookbook: https://github.com/mistralai/cookbook/blob/main/mistral/fine_tune/pixtral_finetune_on_satellite_data.ipynb
Contact Us
Interested in more custom work with the Mistral AI team? Contact us for solution support and discover how we can help you achieve your AI goals.