



Voice: the original UI.
Voice was humanity’s first interface—long before writing or typing, it let us share ideas, coordinate work, and build relationships. As digital systems become more capable, voice is returning as our most natural form of human-computer interaction.
Yet today’s systems remain limited—unreliable, proprietary, and too brittle for real-world use. Closing this gap demands tools with exceptional transcription, deep understanding, multilingual fluency, and open, flexible deployment.
We release the Voxtral models to accelerate this future. These state‑of‑the‑art speech understanding models are available in two sizes—a 24B variant for production-scale applications and a 3B variant for local and edge deployments. Both versions are released under the Apache 2.0 license, and are also available on our API. The API routes transcription queries to a transcribe-optimized version of Voxtral Mini (Voxtral Mini Transcribe) that delivers unparalleled cost and latency-efficiency. For a comprehensive understanding of the research and development behind Voxtral, please refer to our detailed research paper, available for download here.
Open, affordable, and production-ready speech understanding for everyone.
Until recently, gaining truly usable speech intelligence in production meant choosing between two trade-offs:
Open-source ASR systems with high word error rates and limited semantic understanding
Closed, proprietary APIs that combine strong transcription with language understanding, but at significantly higher cost and with less control over deployment
Voxtral bridges this gap. It offers state-of-the-art accuracy and native semantic understanding in the open, at less than half the price of comparable APIs. This makes high-quality speech intelligence accessible and controllable at scale.
Both Voxtral models go beyond simple transcription with capabilities that include:
Long-form context: with a 32k token context length, Voxtral handles audios up to 30 minutes for transcription, or 40 minutes for understanding
Built-in Q&A and summarization: Supports asking questions directly about the audio content or generating structured summaries, without the need to chain separate ASR and language models
Natively multilingual: Automatic language detection and state-of-the-art performance in the world’s most widely used languages (English, Spanish, French, Portuguese, Hindi, German, Dutch, Italian, to name a few), helping teams serve global audiences with a single system
Function-calling straight from voice: Enables direct triggering of backend functions, workflows, or API calls based on spoken user intents, turning voice interactions into actionable system commands without intermediate parsing steps.
Highly capable at text: Retains the text understanding capabilities of its language model backbone, Mistral Small 3.1
These capabilities make the Voxtral models ideal for real-world interactions and downstream actions, such as summaries, answers, analysis, and insights. For cost-sensitive use-cases, Voxtral Mini Transcribe outperforms OpenAI Whisper for less than half the price. For premium use cases, Voxtral Small matches the performance of ElevenLabs Scribe, also for less than half the price.
Benchmarks
Speech Transcription
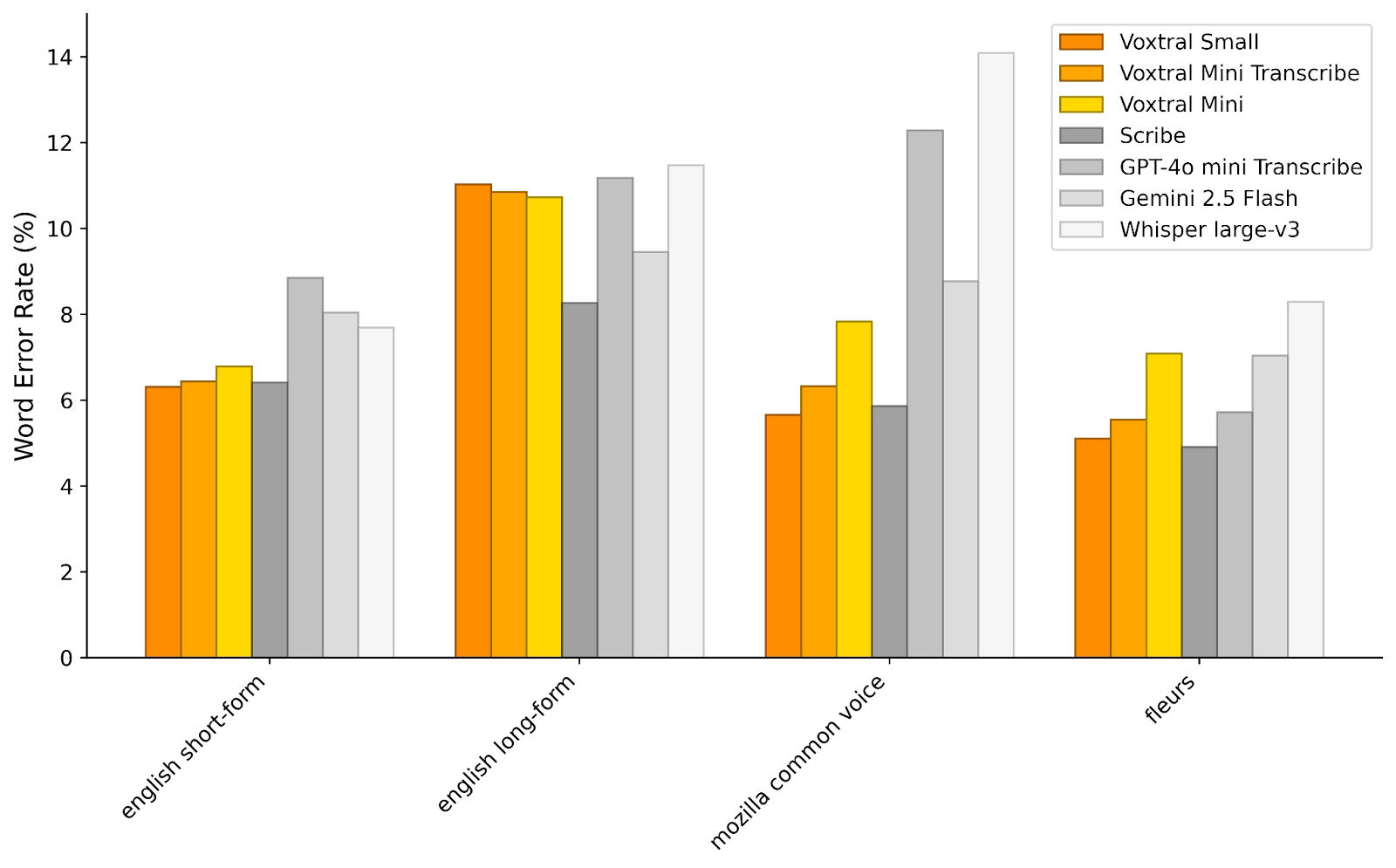
To assess Voxtral’s transcription capabilities, we evaluate it on a range of English and multilingual benchmarks. For each task, we report the macro-average word error rate (lower is better) across languages. For English, we report a short-form (<30-seconds) and long-form (>30-seconds) average.
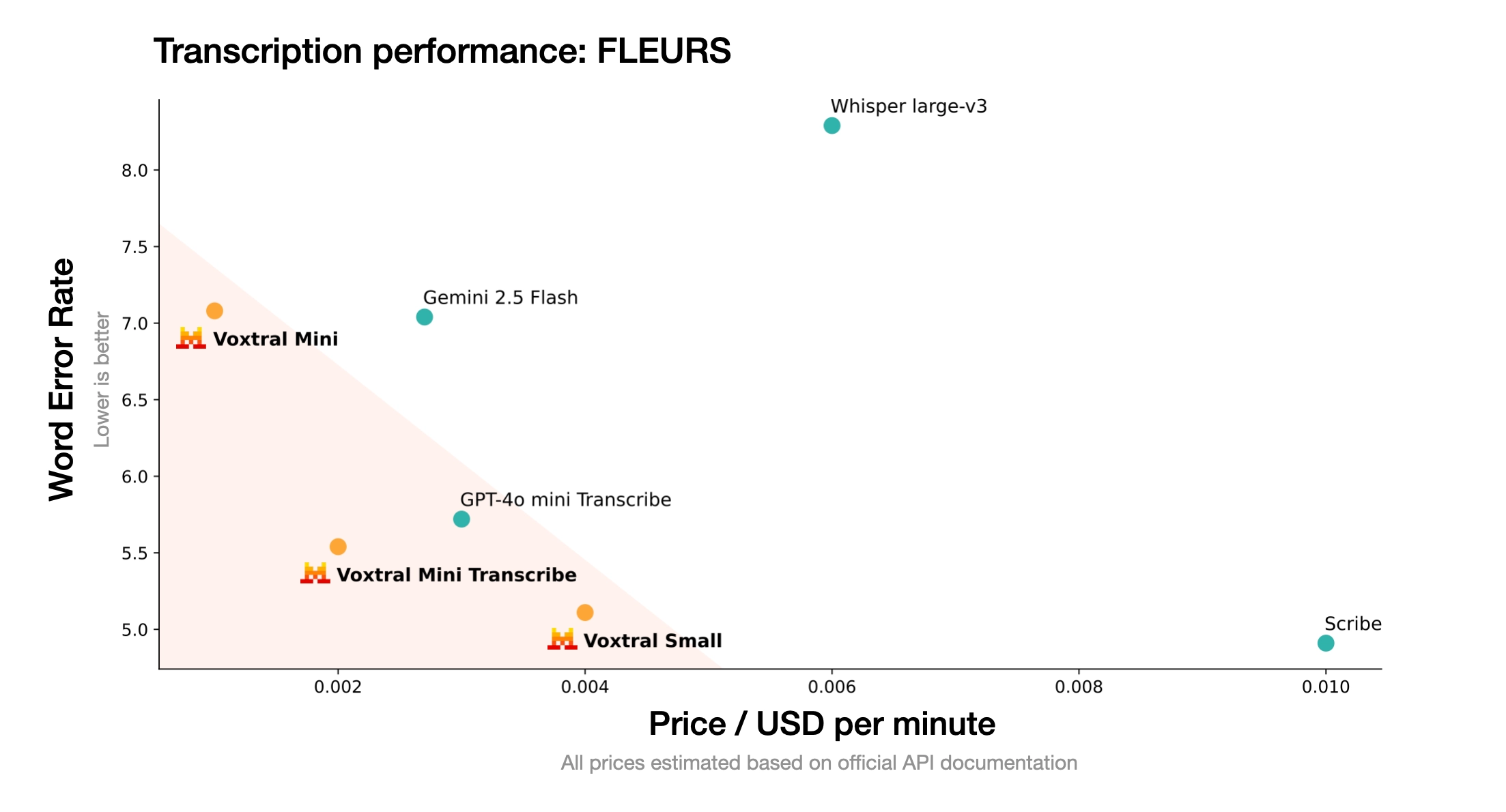
Voxtral comprehensively outperforms Whisper large-v3, the current leading open-source Speech Transcription model. It beats GPT-4o mini Transcribe and Gemini 2.5 Flash across all tasks, and achieves state-of-the-art results on English short-form and Mozilla Common Voice, surpassing ElevenLabs Scribe and demonstrating its strong multilingual capabilities.
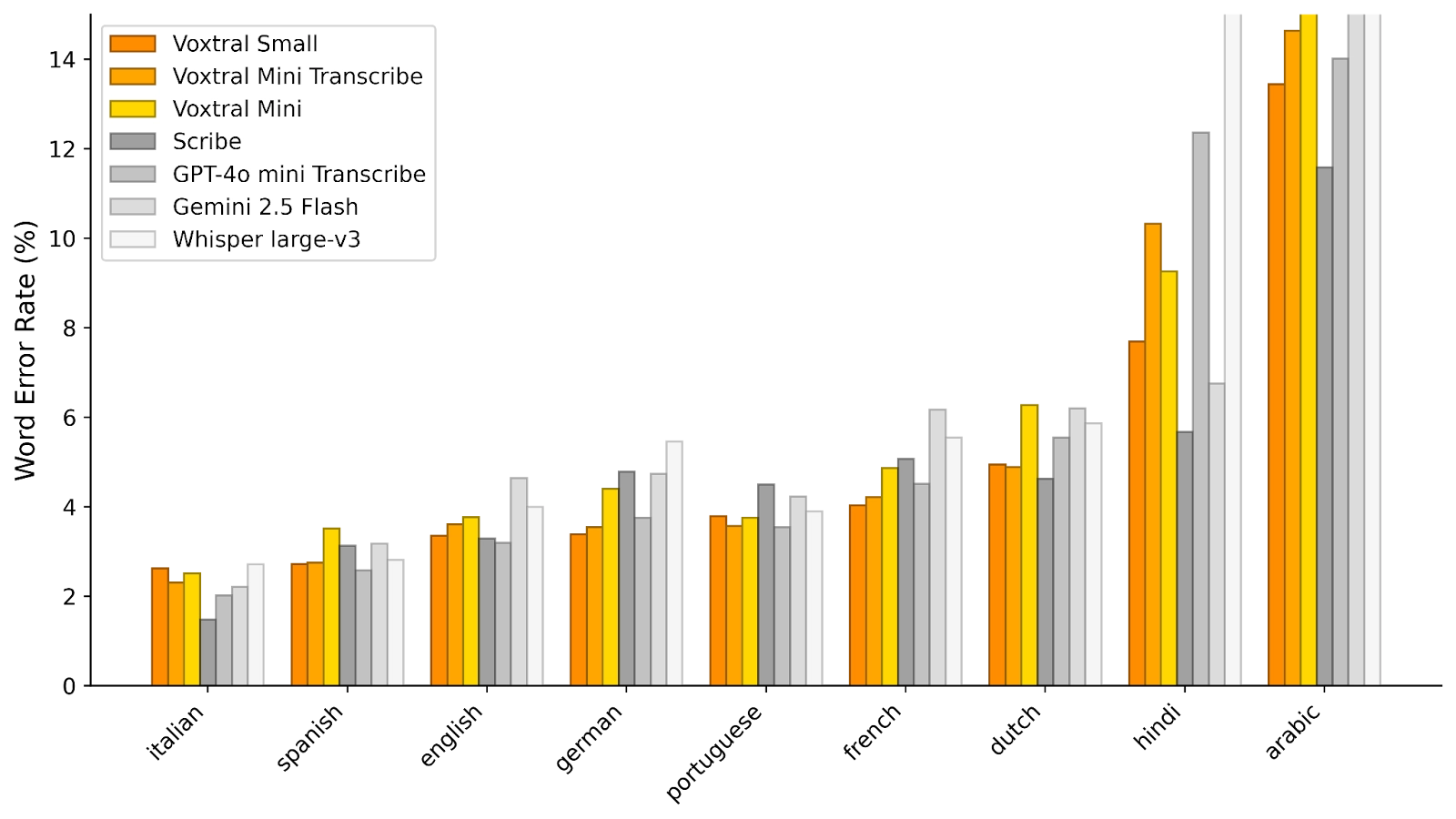
When evaluated across languages in FLEURS, Voxtral Small outperforms Whisper on every task, achieving state-of-the-art performance in a number of European languages.
Macro-average details:
En short-form: LibriSpeech Clean, LibriSpeech Other, GigaSpeech, VoxPopuli, Switchboard, CHiME-4, SPGISpeech
En long-form: Earnings-21 10-m, Earnings-22 10-m
Mozilla Common Voice 15.1: English, French, German, Spanish, Italian, Portuguese, Dutch, Hindi
FLEURS: English, French, German, Spanish, Italian, Portuguese, Dutch, Hindi, Arabic
Audio Understanding
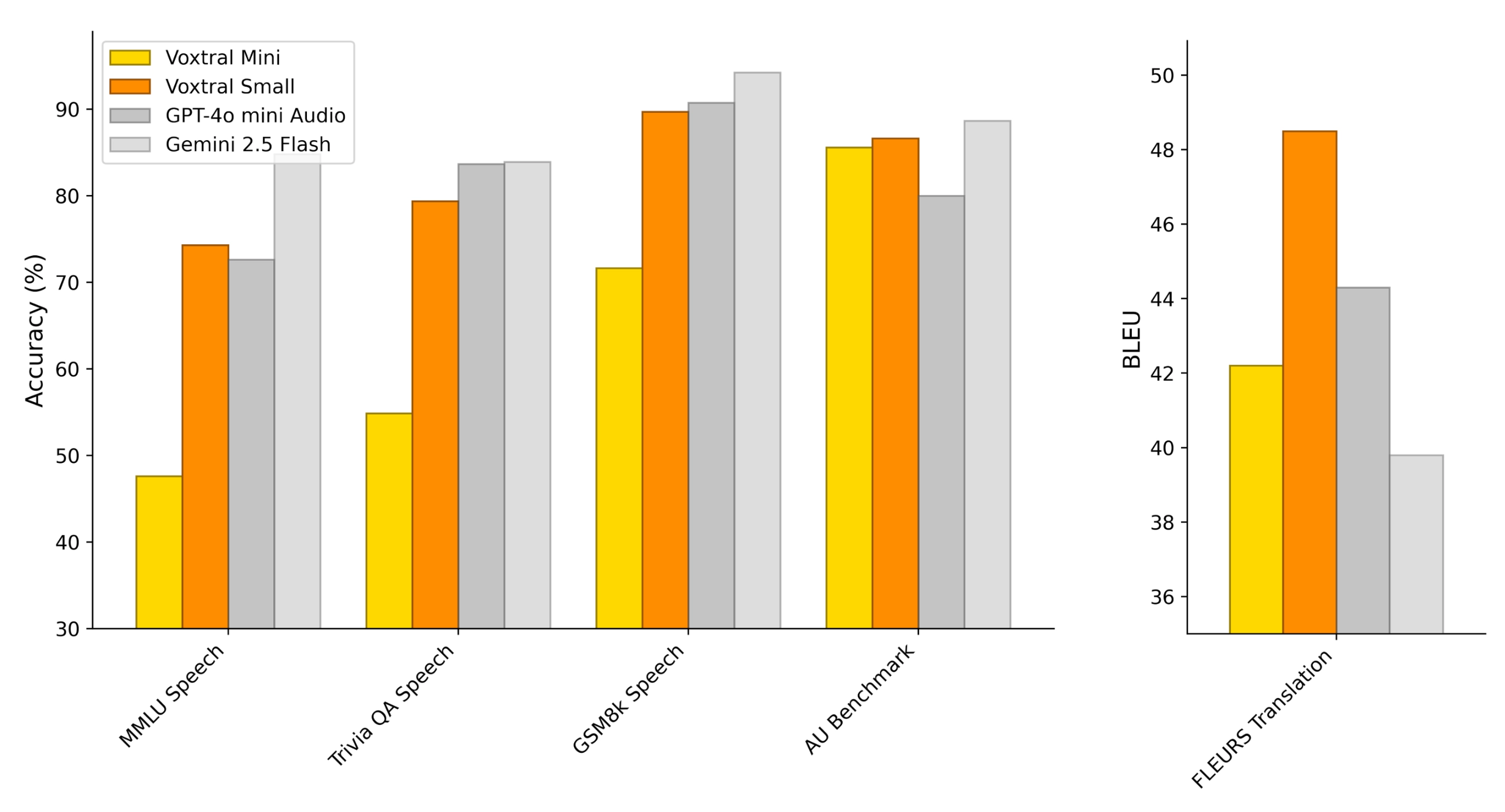
Voxtral Small and Mini are capable of answering questions directly from speech, or by providing an audio and a text-based prompt. To evaluate Audio Understanding capabilities, we create speech-synthesized versions of three common Text Understanding tasks. We also evaluate the models on an in-house Audio Understanding (AU) Benchmark, where the model is tasked with answering challenging questions on 40 long-form audio examples. Finally, we assess Speech Translation capabilities on the FLEURS-Translation benchmark.
Voxtral Small is competitive with GPT-4o-mini and Gemini 2.5 Flash across all tasks, achieving state-of-the-art performance in Speech Translation.
Text
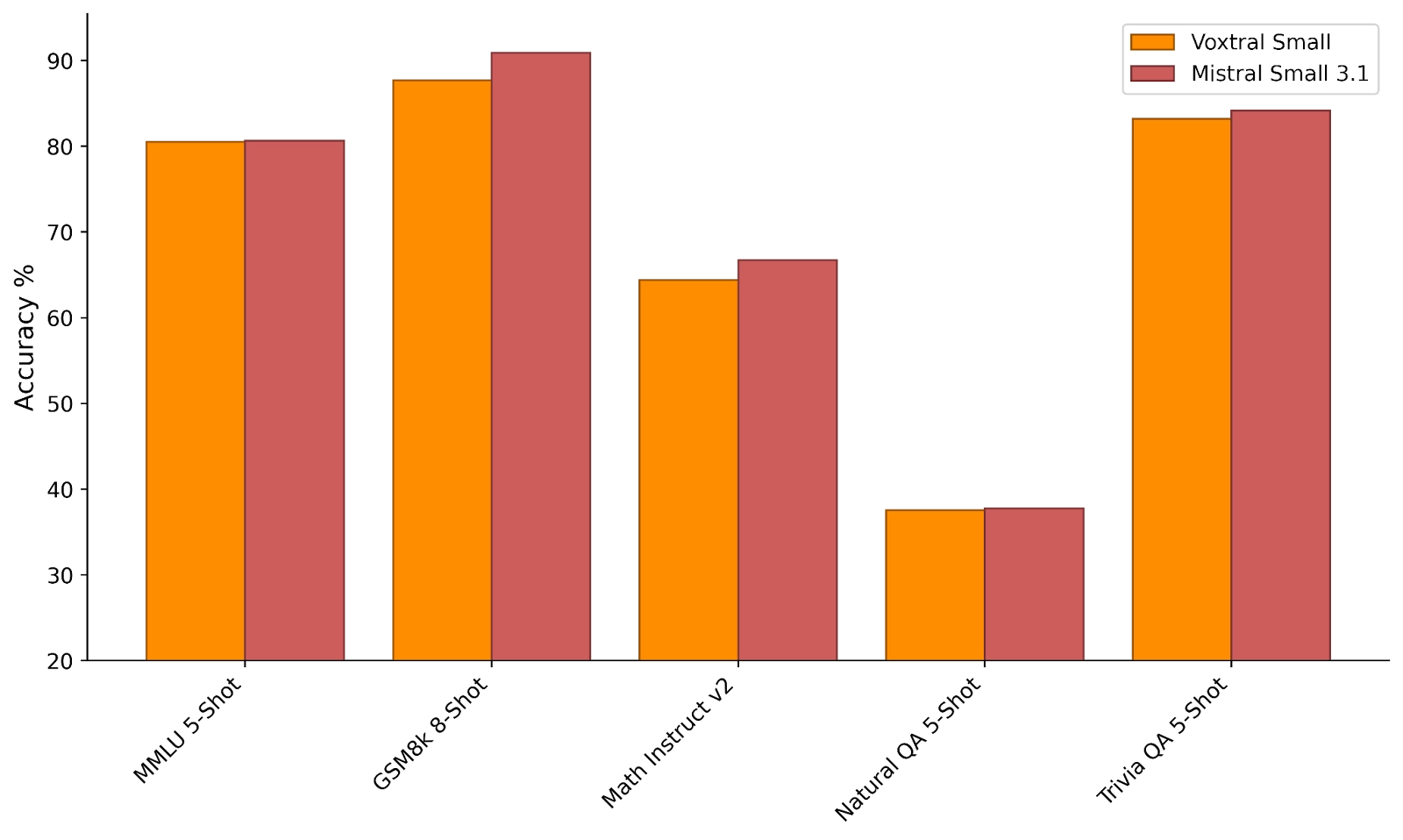
Voxtral retains the text capabilities of its Language-Model backbone, enabling it to be used as a drop-in replacement for Ministral and Mistral Small 3.1 respectively.
Try it for free
Whether you’re prototyping on a laptop, running private workloads on-premises, or scaling to production in the cloud, getting started is straightforward.
Download and run locally: Both Voxtral (24B) and Voxtral Mini (3B) are available to download on Hugging Face
Try the API: Integrate frontier speech intelligence into your application with a single API call. Pricing starts at $0.001 per minute, making high-quality transcription and understanding affordable at scale. Check out our documentation here.
Try it on Le Chat: Try Voxtral in Le Chat’s voice mode (rolling out to all users in the next couple of weeks)—on web or mobile. Record or upload audio, get transcriptions, ask questions, or generate summaries.
Advanced enterprise features.
We also offer capabilities for Voxtral designed for enterprises with higher security, scale, or domain-specific requirements. Please reach out to us if you are considering:
Private deployment at production-scale: Our solutions team can help you set up Voxtral for production-scale inference entirely within your own infrastructure. This is ideal for use cases in regulated industries with strict data privacy requirements. This includes guidance and tooling for deploying Voxtral across multiple GPUs or nodes, with quantized builds optimized for production throughput and cost efficiency.
Domain-specific fine-tuning: Work with our applied AI team to adapt Voxtral to specialized contexts—such as legal, medical, customer support, or internal knowledge bases—improving accuracy for your use case.
Advanced context: We’re inviting design partners to build support for speaker identification, emotion detection, advanced diarization, and even longer context windows to meet a wider variety of needs out of the box.
Dedicated integration support: Priority access to engineering resources and consulting to help integrate Voxtral cleanly into your existing workflows, products, or data pipelines.
Coming up.
We will be hosting a live webinar with our friends at Inworld (check out their cool speech-to-speech demo with Voxtral and Inworld TTS!) to showcase how you can build end-to-end voice-powered agents on Wednesday, Aug 6. If you’re interested, please register here.
We’re working on making our audio capabilities more feature-rich in the forthcoming months. In addition to speech understanding, will we soon support:
Speaker segmentation
Audio markups such as age and emotion
Word-level timestamps
Non-speech audio recognition
And more!
We’re excited to see what you will build with Voxtral.
BTW, we’re hiring!
The release of our Voxtral models marks a significant step forward, but our journey is far from over. Our ambition is to build the most natural, delightful near-human-like voice interfaces and there's lot more work to do. We are actively expanding our nascent audio team and looking for talented research scientists and engineers who share our ambition.
If you’re interested in joining us on our mission to democratize artificial intelligenceI, we welcome your applications to join our team!