Build.
Connect your data sources. Orchestrate your business logic. Ship AI that holds up under real conditions.
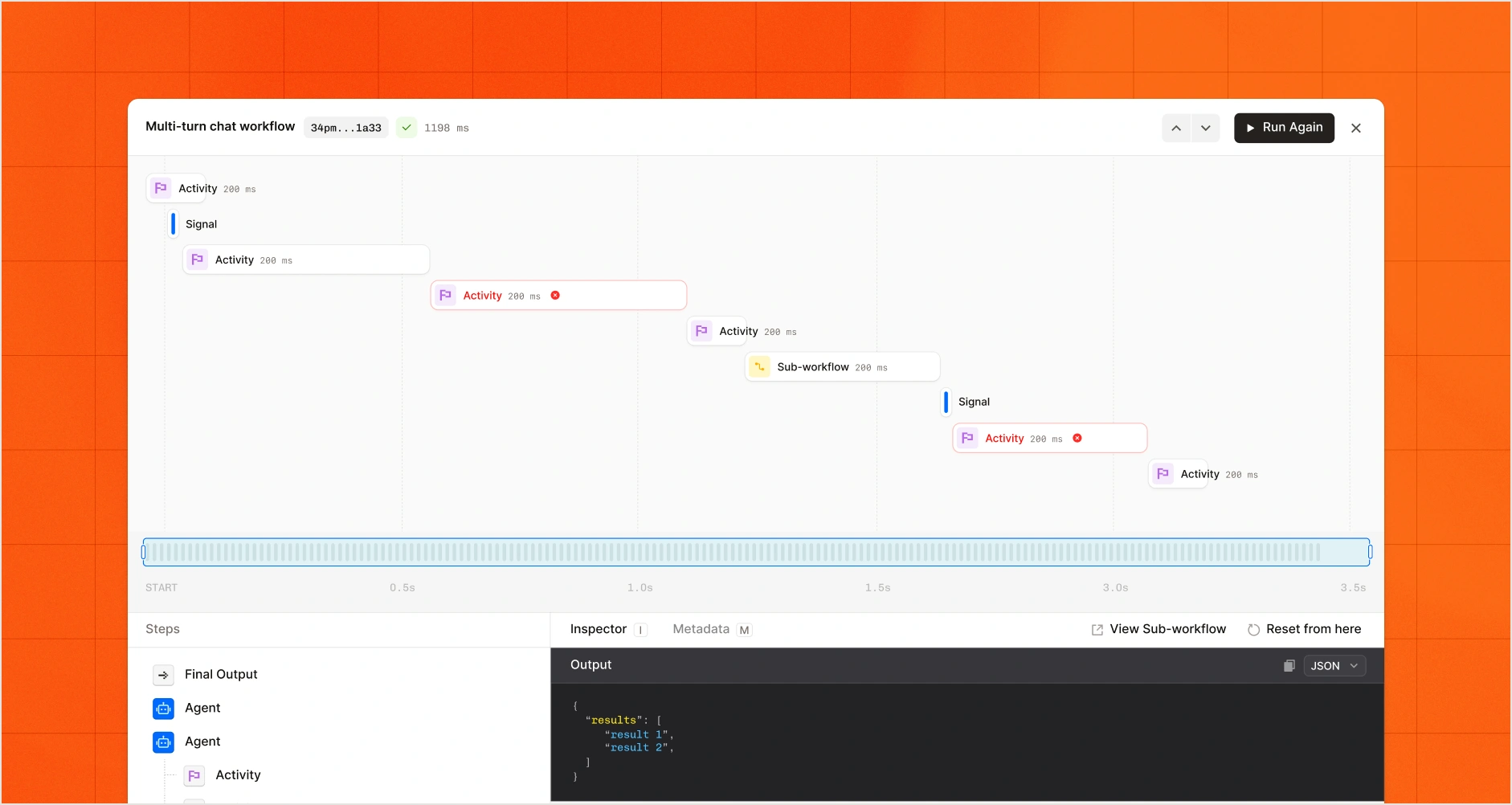
Workflows.
Orchestrate agentic processes that persist state, retry on failure, and resume automatically.
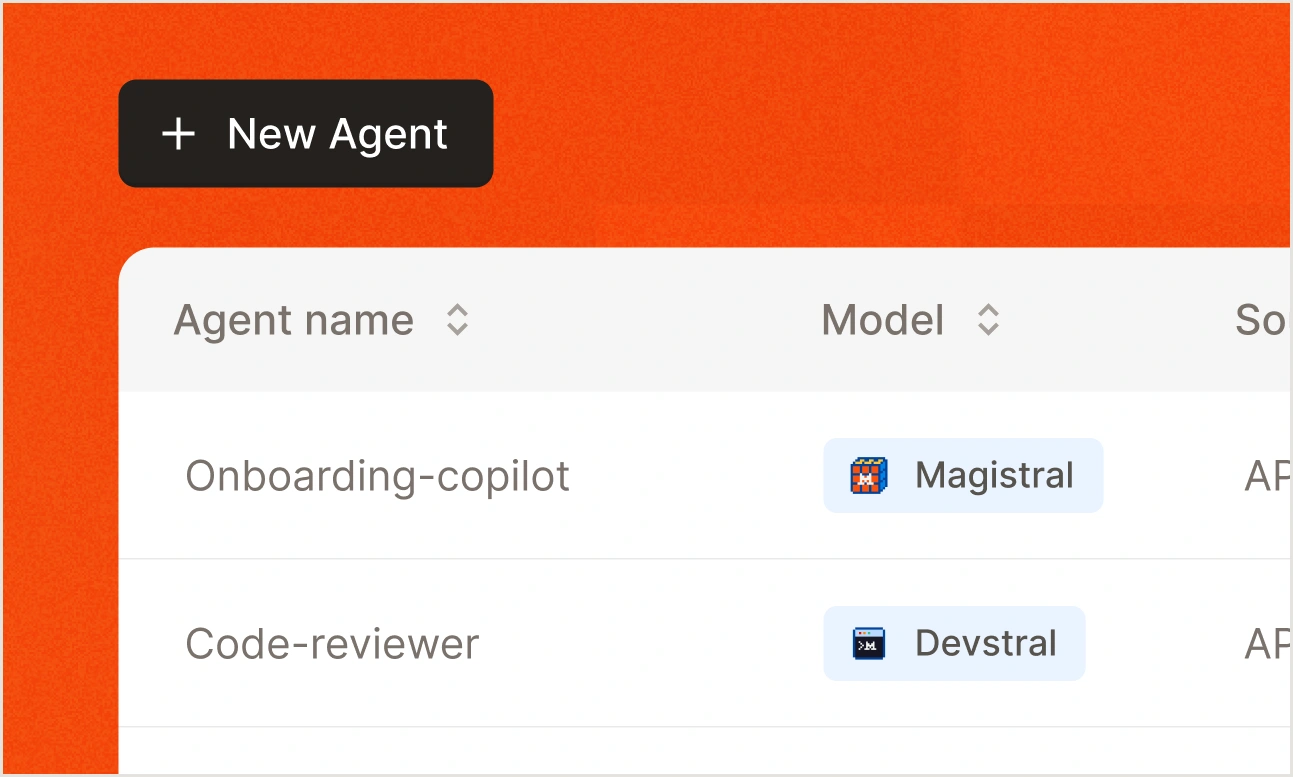
Agents.
Design AI agents that reason across tools, data, and systems. Define instructions and control behavior before anything reaches production.
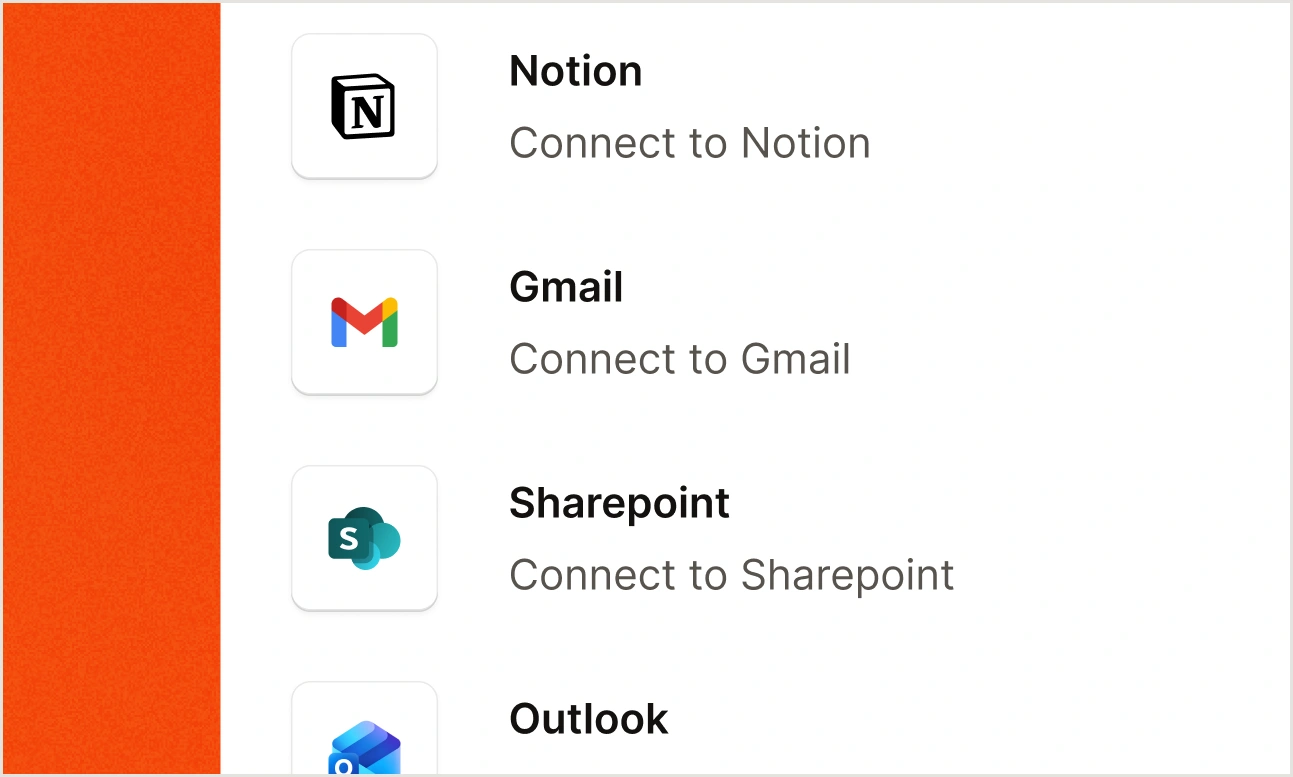
Connectors.
Connect to any enterprise data source with built-in or custom connectors. Build once, reuse across every agent and workflow.
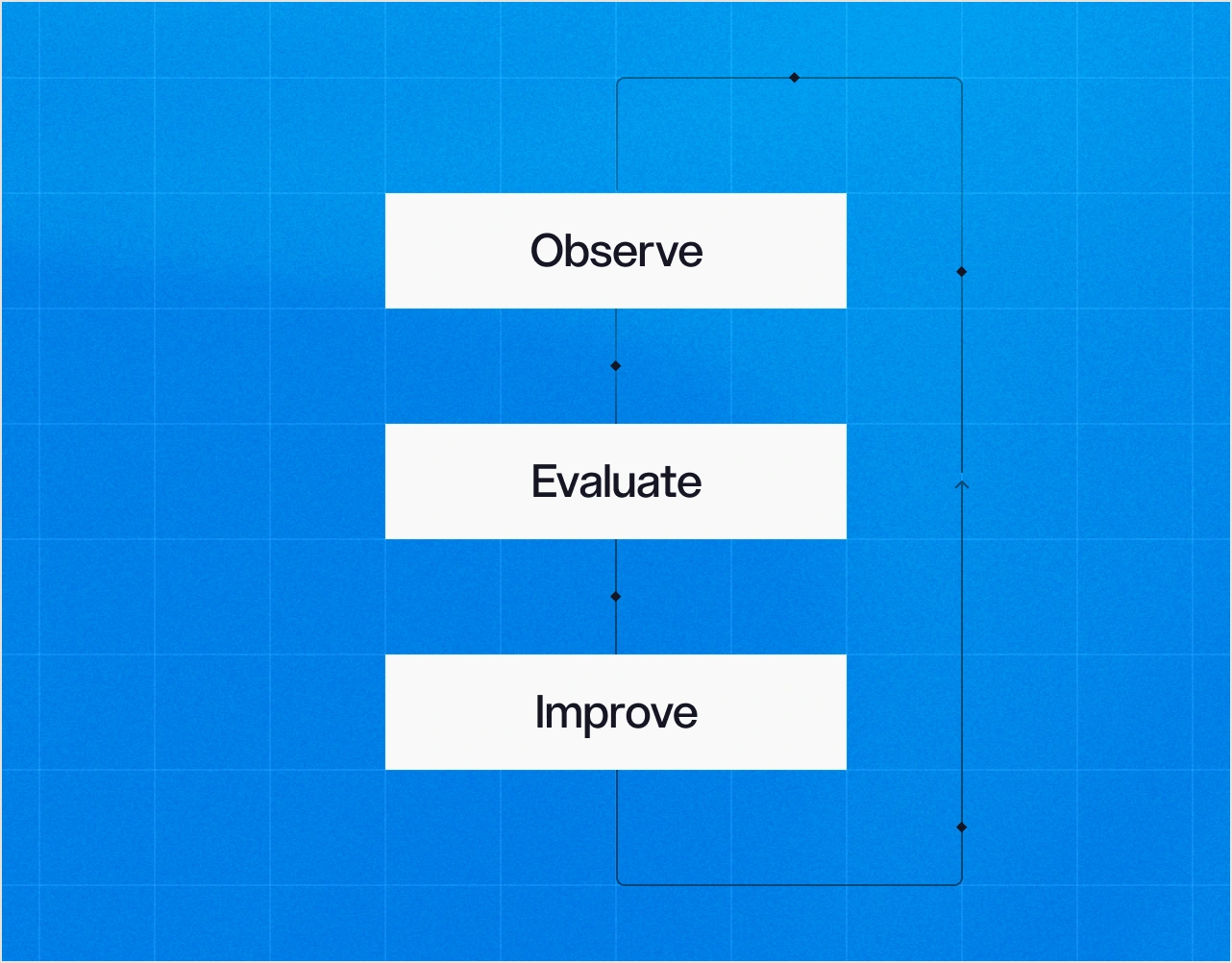
Iterate.
Measure what your AI actually does. Then make it better.
Experiments.
Design and compare model variations in controlled environments. Test changes before they reach users.
Campaigns.
Run reproducible, versioned iterations. Track what changed, what improved, and what broke.
Judges.
Score outputs automatically with built-in or custom evaluation models. Replace subjective review with consistent, interpretable metrics.
Datasets.
Turn real traffic and production feedback into curated training data. Every interaction becomes an opportunity to improve.
Deploy.
Run anywhere. Your infrastructure, your rules.
Hybrid.
Deploy across cloud and on-prem environments with consistent behavior. One codebase, any infrastructure.
Dedicated.
Isolate workloads for security, compliance, or performance. Separate environments, no shared resources.
Self-hosted.
Retain full control over infrastructure and data residency. Nothing leaves your perimeter.
Govern.
See everything. Control what matters.
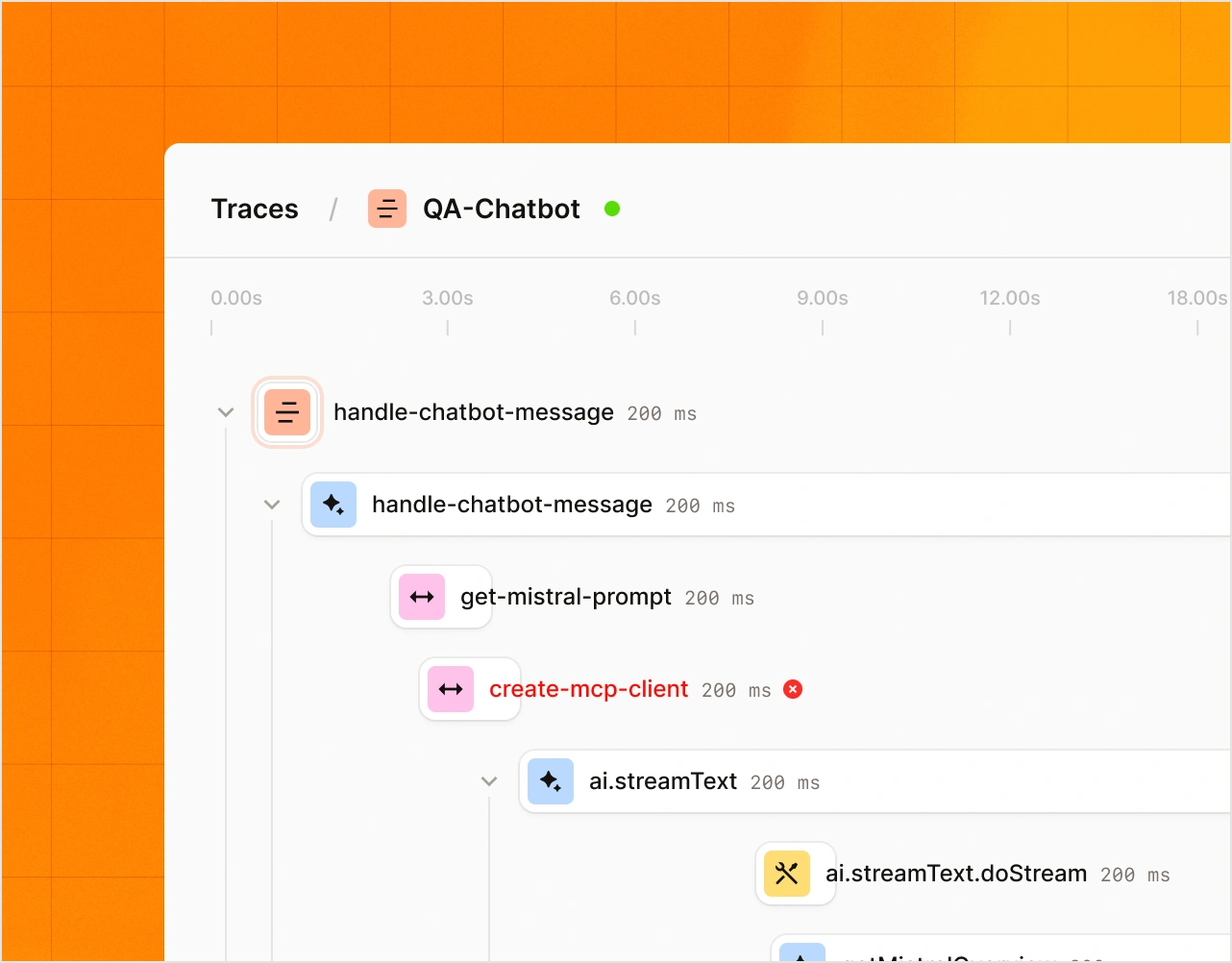
Observability.
Visualize every request, response, and decision across multi-step pipelines. Traces, dashboards, and context graphs in real time.
Guardrails.
Enforce behavioral and policy constraints at runtime. Define what your AI can and cannot do, in code.

Moderation.
Detect and filter unsafe or non-compliant outputs automatically. Policies run on every response, not as an afterthought.

Accelerate.
The first AI use case can be time consuming. The next 10 shouldn't be.
AI registry.
A unified catalog for models, agents, prompts, skills, datasets, and workflows. Full lineage and access controls, all in one place.

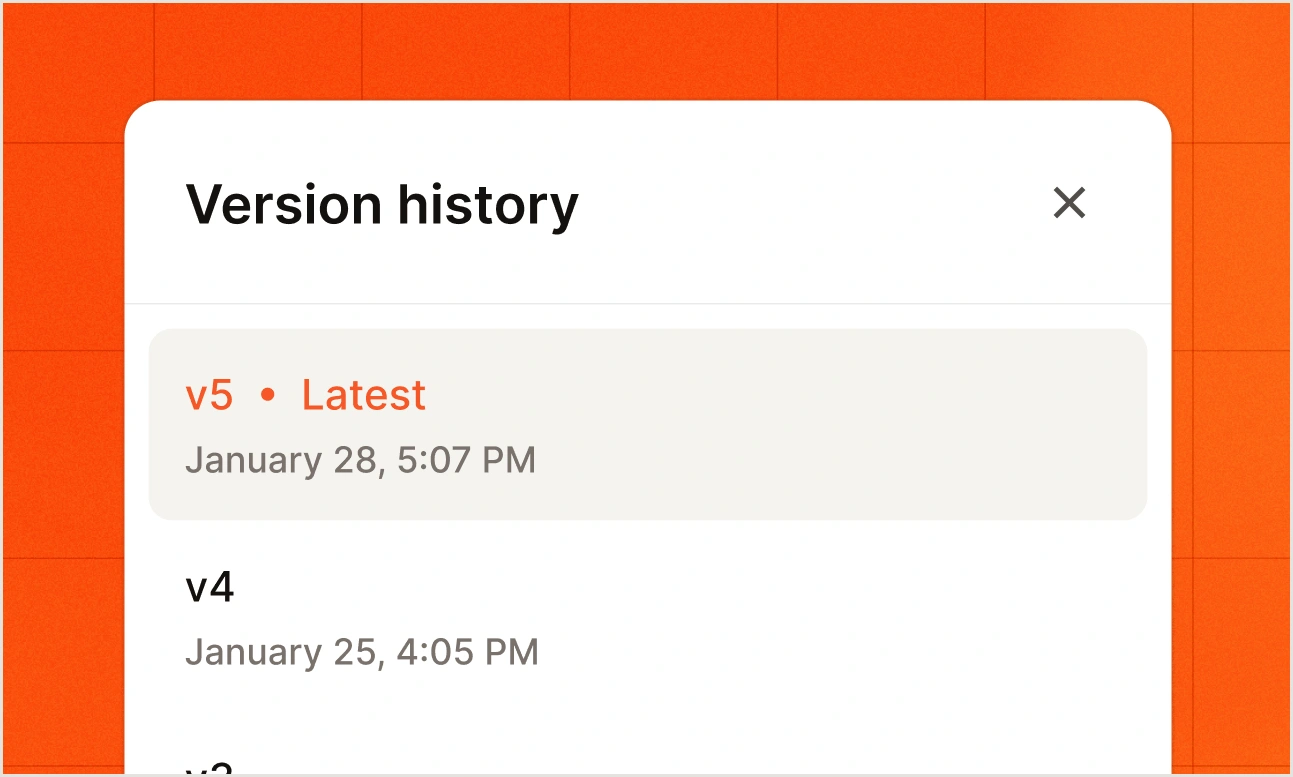
Versioning and lineage.
Track every change across teams. Reuse assets confidently. Roll back instantly when needed.
Developer toolkit.
APIs, SDKs, code samples, and pre-built components. Everything you need to start building in minutes, not weeks.

Build what’s next.