




Today, we announce Mistral 3, the next generation of Mistral models. Mistral 3 includes three state-of-the-art small, dense models (14B, 8B, and 3B) and Mistral Large 3 – our most capable model to date – a sparse mixture-of-experts trained with 41B active and 675B total parameters. All models are released under the Apache 2.0 license. Open-sourcing our models in a variety of compressed formats empowers the developer community and puts AI in people’s hands through distributed intelligence.
The Ministral models represent the best performance-to-cost ratio in their category. At the same time, Mistral Large 3 joins the ranks of frontier instruction-fine-tuned open-source models.
Mistral Large 3: A state-of-the-art open model
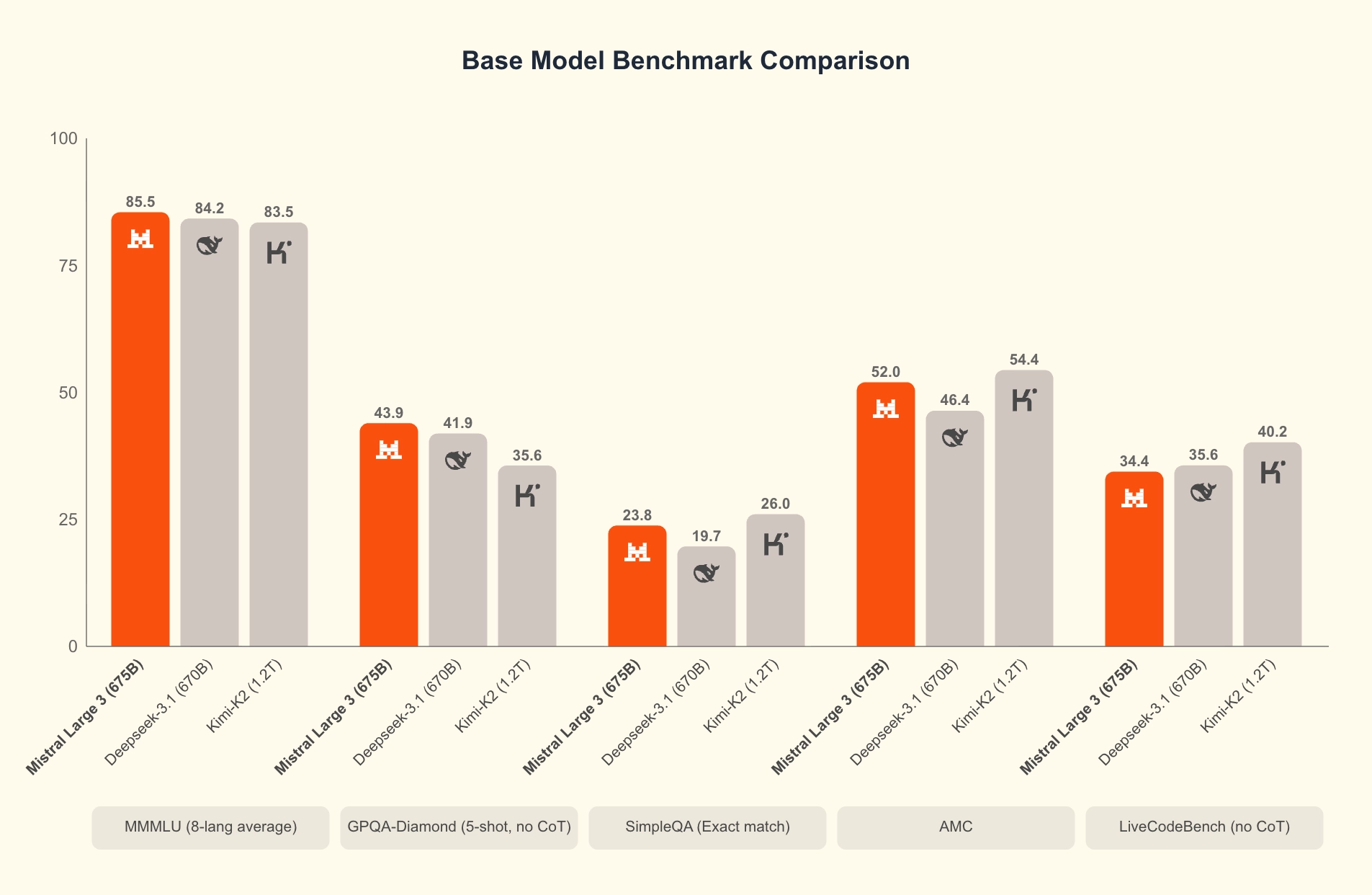
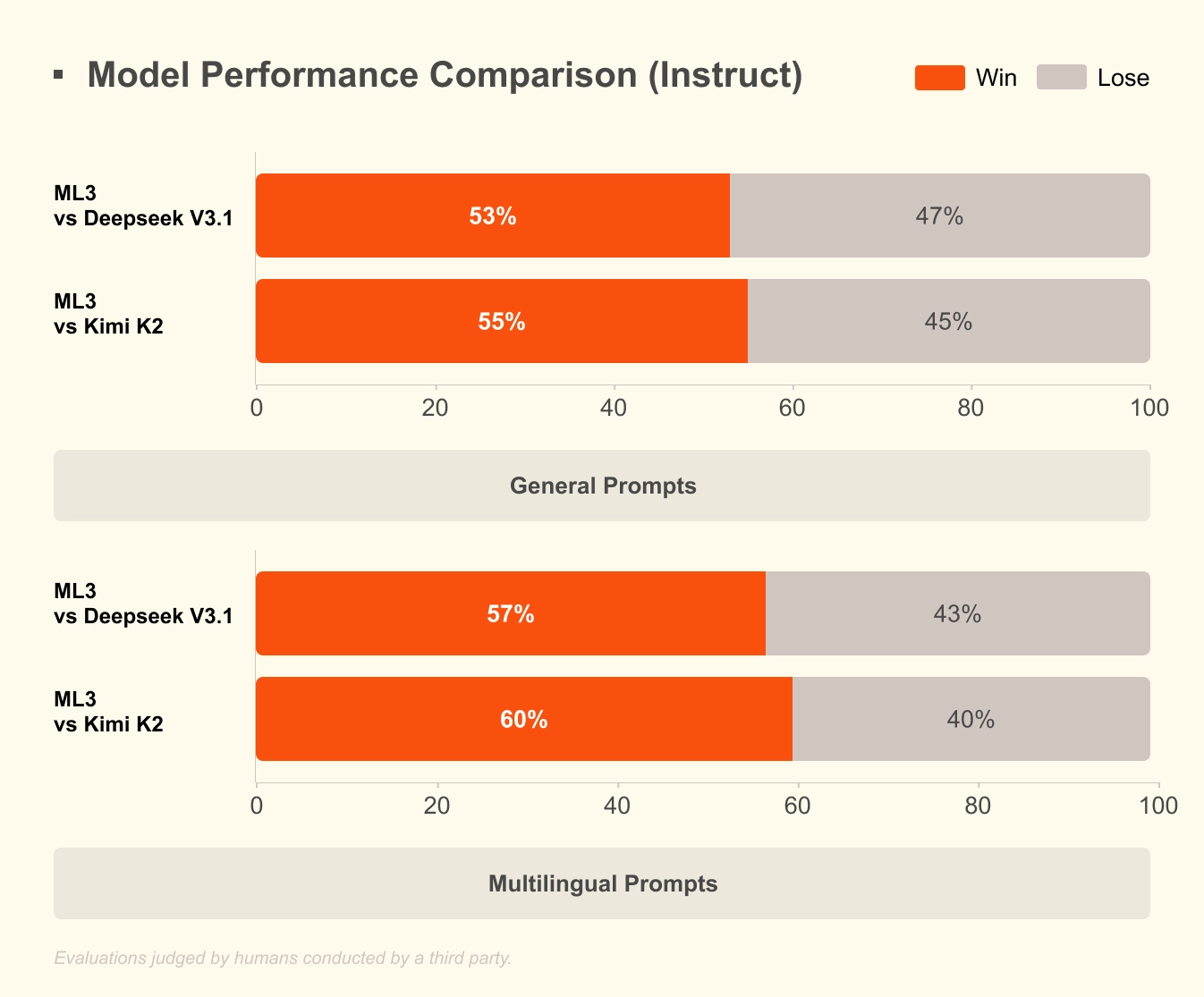
Mistral Large 3 is one of the best permissive open weight models in the world, trained from scratch on 3000 of NVIDIA’s H200 GPUs. Mistral Large 3 is Mistral’s first mixture-of-experts model since the seminal Mixtral series, and represents a substantial step forward in pretraining at Mistral. After post-training, the model achieves parity with the best instruction-tuned open-weight models on the market on general prompts, while also demonstrating image understanding and best-in-class performance on multilingual conversations (i.e., non-English/Chinese).
Mistral Large 3 debuts at #2 in the OSS non-reasoning models category (#6 amongst OSS models overall) on the LMArena leaderboard.
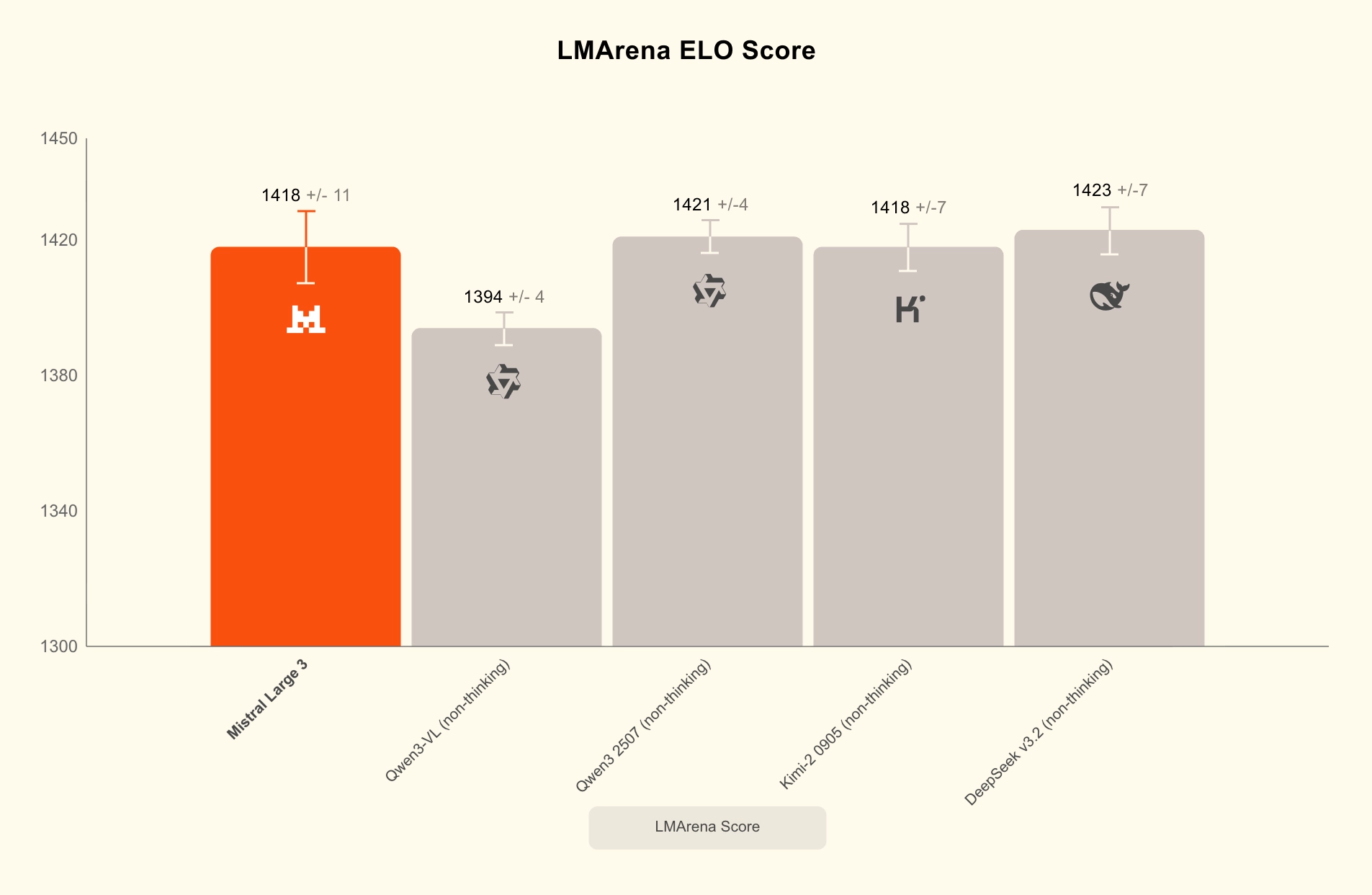
We release both the base and instruction fine-tuned versions of Mistral Large 3 under the Apache 2.0 license, providing a strong foundation for further customization across the enterprise and developer communities. A reasoning version is coming soon!
Mistral, NVIDIA, vLLM & Red Hat join forces to deliver faster, more accessible Mistral 3
Working in conjunction with vLLM and Red Hat, Mistral Large 3 is very accessible to the open-source community. We’re releasing a checkpoint in NVFP4 format, built with llm-compressor. This optimized checkpoint lets you run Mistral Large 3 efficiently on Blackwell NVL72 systems and on a single 8×A100 or 8×H100 node using vLLM.
Delivering advanced open-source AI models requires broad optimization, achieved through a partnership with NVIDIA. All our new Mistral 3 models, from Large 3 to Ministral 3, were trained on NVIDIA Hopper GPUs to tap high-bandwidth HBM3e memory for frontier-scale workloads. NVIDIA’s extreme co-design approach brings hardware, software, and models together. NVIDIA engineers enabled efficient inference support for TensorRT-LLM and SGLang for the complete Mistral 3 family, for efficient low-precision execution.
For Large 3’s sparse MoE architecture, NVIDIA integrated state-of-the-art Blackwell attention and MoE kernels, added support for prefill/decode disaggregated serving, and collaborated with Mistral on speculative decoding, enabling developers to efficiently serve long-context, high-throughput workloads on GB200 NVL72 and beyond. On the edge, delivers optimized deployments of the Ministral models on DGX Spark, RTX PCs and laptops, and Jetson devices, giving developers a consistent, high-performance path to run these open models from data center to robot.
We are very thankful for the collaboration and want to thank vLLM, Red Hat, and NVIDIA in particular.
Ministral 3: State-of-the-art intelligence at the edge
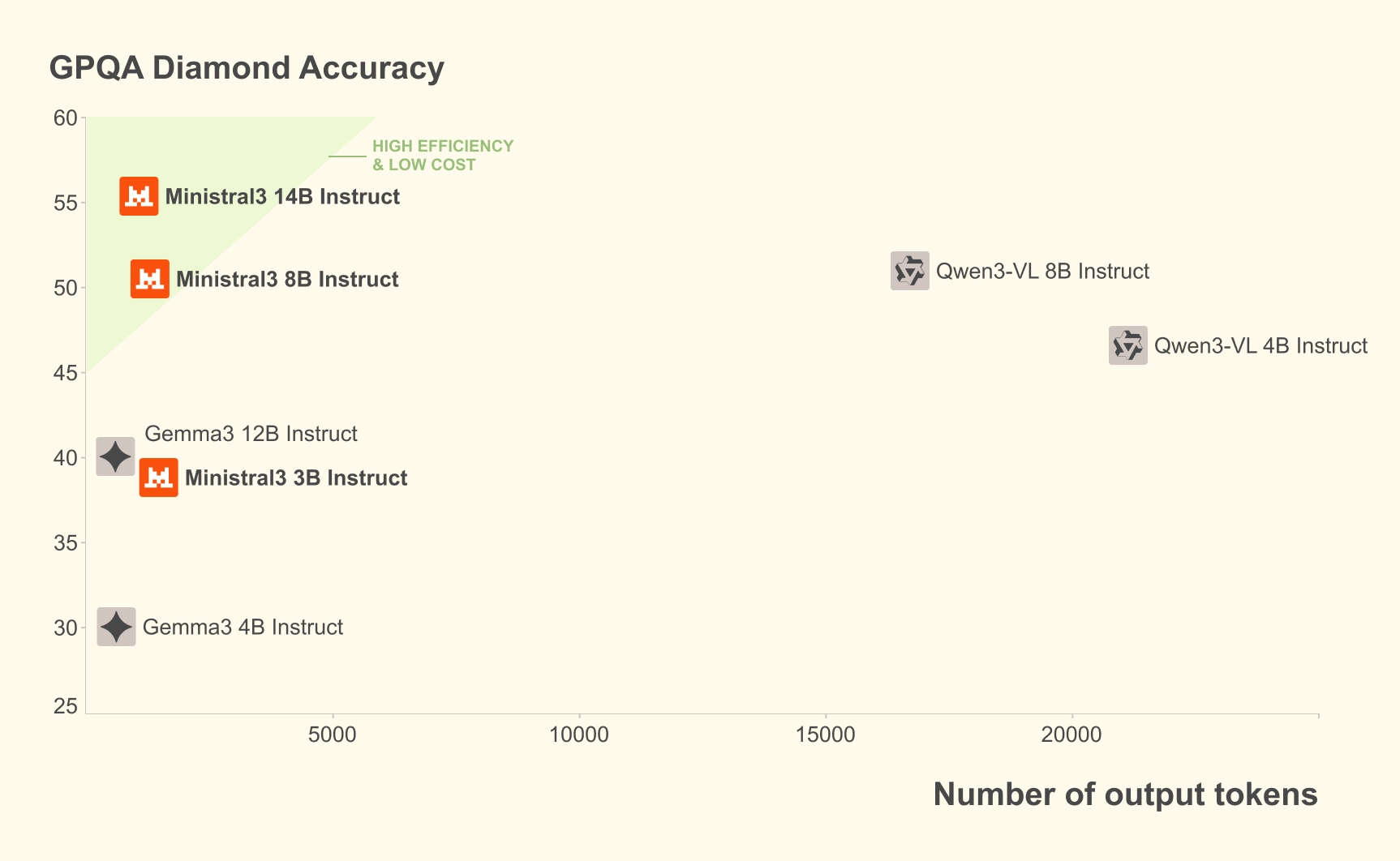
For edge and local use cases, we release the Ministral 3 series, available in three model sizes: 3B, 8B, and 14B parameters. Furthermore, for each model size, we release base, instruct, and reasoning variants to the community, each with image understanding capabilities, all under the Apache 2.0 license. When married with the models’ native multimodal and multilingual capabilities, the Ministral 3 family offers a model for all enterprise or developer needs.
Furthermore, Ministral 3 achieves the best cost-to-performance ratio of any OSS model. In real-world use cases, both the number of generated tokens and model size matter equally. The Ministral instruct models match or exceed the performance of comparable models while often producing an order of magnitude fewer tokens.
For settings where accuracy is the only concern, the Ministral reasoning variants can think longer to produce state-of-the-art accuracy amongst their weight class - for instance 85% on AIME ‘25 with our 14B variant.
Available Today
Mistral 3 is available today on Mistral AI Studio, Amazon Bedrock, Azure Foundry, Hugging Face (Large 3 & Ministral), Modal, IBM WatsonX, OpenRouter, Fireworks, Unsloth AI,and Together AI. In addition, coming soon on NVIDIA NIM and AWS SageMaker.
One more thing… customization with Mistral AI
For organizations seeking tailored AI solutions, Mistral AI offers custom model training services to fine-tune or fully adapt our models to your specific needs. Whether optimizing for domain-specific tasks, enhancing performance on proprietary datasets, or deploying models in unique environments, our team collaborates with you to build AI systems that align with your goals. For enterprise-grade deployments, custom training ensures your AI solution delivers maximum impact securely, efficiently, and at scale.
Get started with Mistral 3
The future of AI is open. Mistral 3 redefines what’s possible with a family of models built for frontier intelligence, multimodal flexibility, and unmatched customization. Whether you’re deploying edge-optimized solutions with Ministral 3 or pushing the boundaries of reasoning with Mistral Large 3, this release puts state-of-the-art AI directly into your hands.
Why Mistral 3?
Frontier performance, open access: Achieve closed-source-level results with the transparency and control of open-source models.
Multimodal and multilingual: Build applications that understand text, images, and complex logic across 40+ native languages.
Scalable efficiency: From 3B to 675B parameters, choose the model that fits your needs, from edge devices to enterprise workflows.
Agentic and adaptable: Deploy for coding, creative collaboration, document analysis, or tool-use workflows with precision.
Next Steps
Explore the model documentation:
Technical documentation for customers is available on our AI Governance Hub
Start building: Ministral 3 and Large 3 on Hugging Face, or deploy via Mistral AI’s platform for instant API access and API pricing
Customize for your needs: Need a tailored solution? Contact our team to explore fine-tuning or enterprise-grade training.
Share your projects, questions, or breakthroughs with us: Twitter/X, Discord, or GitHub.
Alongside this launch, you can explore the full details of the Ministral 3 series architecture in our latest research paper here.
We believe that the future of AI should be built on transparency, accessibility, and collective progress. With this release, we invite the world to explore, build, and innovate with us, unlocking new possibilities in reasoning, efficiency, and real-world applications.
Together, let’s turn understanding into action.