



Following the publishing of the Mixtral family, Codestral Mamba is another step in our effort to study and provide new architectures. It is available for free use, modification, and distribution, and we hope it will open new perspectives in architecture research. Codestral Mamba was designed with help from Albert Gu and Tri Dao.
Unlike Transformer models, Mamba models offer the advantage of linear time inference and the theoretical ability to model sequences of infinite length. It allows users to engage with the model extensively with quick responses, irrespective of the input length. This efficiency is especially relevant for code productivity use cases—this is why we trained this model with advanced code and reasoning capabilities, enabling it to perform on par with SOTA transformer-based models.
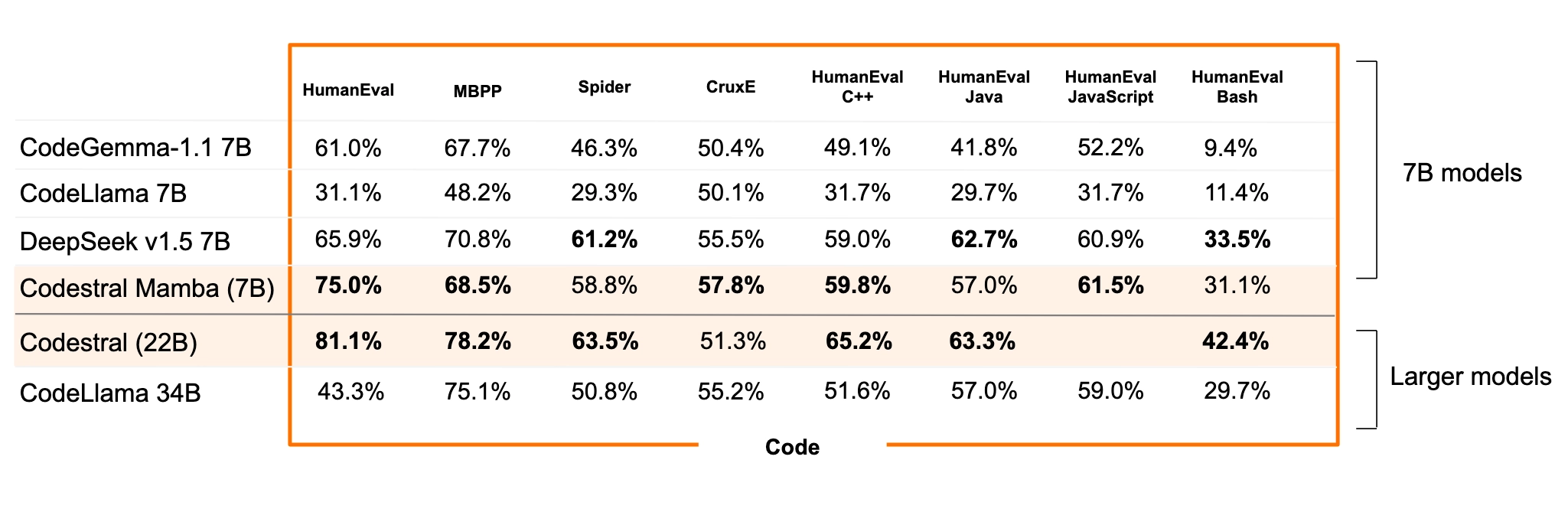
We have tested Codestral Mamba on in-context retrieval capabilities up to 256k tokens. We expect it to be a great local code assistant!
You can deploy Codestral Mamba using the mistral-inference SDK, which relies on the reference implementations from Mamba's GitHub repository. The model can also be deployed through TensorRT-LLM. For local inference, keep an eye out for support in llama.cpp. You may download the raw weights from HuggingFace. This is an instructed model, with 7,285,403,648 parameters.
For easy testing, we made Codestral Mamba available on la Plateforme (codestral-mamba-2407), alongside its big sister, Codestral 22B. While Codestral Mamba is available under the Apache 2.0 license, Codestral 22B is available under a commercial license for self-deployment or a community license for testing purposes.