



We are releasing Mistral Large, our latest and most advanced language model. Mistral Large is available through la Plateforme. We are also making it available through Azure, our first distribution partner.
Mistral Large, our new flagship model
Mistral Large is our new cutting-edge text generation model. It reaches top-tier reasoning capabilities. It can be used for complex multilingual reasoning tasks, including text understanding, transformation, and code generation.
Mistral Large achieves strong results on commonly used benchmarks, making it the world's second-ranked model generally available through an API (next to GPT-4) [see below for details on benchmarks].
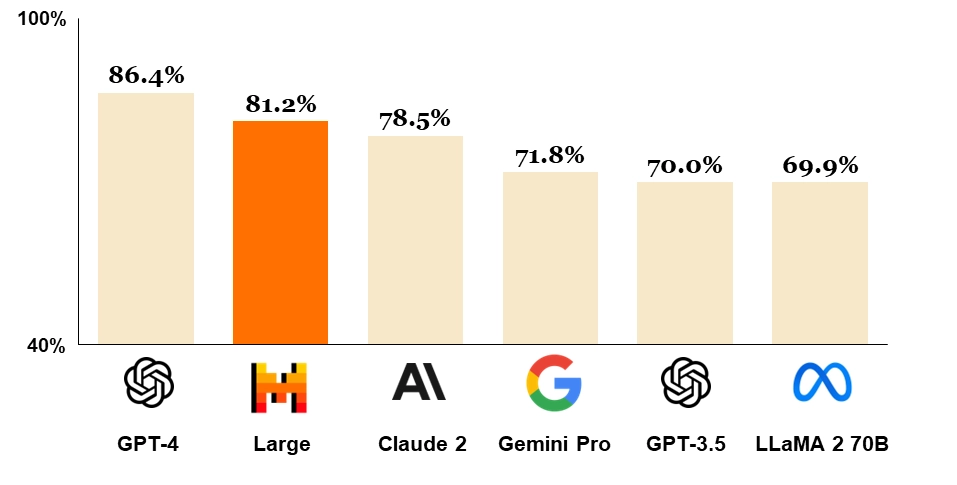
Figure 1: Comparison of GPT-4, Mistral Large (pre-trained), Claude 2, Gemini Pro 1.0, GPT 3.5 and LLaMA 2 70B on MMLU (Measuring massive multitask language understanding).
Mistral Large comes with new capabilities and strengths:
It is natively fluent in English, French, Spanish, German, and Italian, with a nuanced understanding of grammar and cultural context.
Its 32K tokens context window allows precise information recall from large documents.
Its precise instruction-following enables developers to design their moderation policies -- we used it to set up the system-level moderation of le Chat.
It is natively capable of function calling. This, along with constrained output mode, implemented on la Plateforme, enables application development and tech stack modernisation at scale.
Partnering with Microsoft to provide our models on Azure
At Mistral, our mission is to make frontier AI ubiquitous. This is why we're announcing today that we're bringing our open and commercial models to Azure. Microsoft's trust in our model is a step forward in our journey! Our models are now available through:
La Plateforme: safely hosted on Mistral's infrastructure in Europe, this access point enables developers to create applications and services across our comprehensive range of models.
Azure: Mistral Large is available through Azure AI Studio and Azure Machine Learning, with as seamless a user experience as our APIs. Beta customers have used it with significant success.
Self-deployment: our models can be deployed on your environment for the most sensitive use cases with access to our model weights; Read success stories on this kind of deployment, and contact our team for further details.
Mistral Large capacities
We compare Mistral Large's performance to the top-leading LLM models on commonly used benchmarks.
Reasoning and knowledge
Mistral Large shows powerful reasoning capabilities. In the following figure, we report the performance of the pretrained models on standard benchmarks.
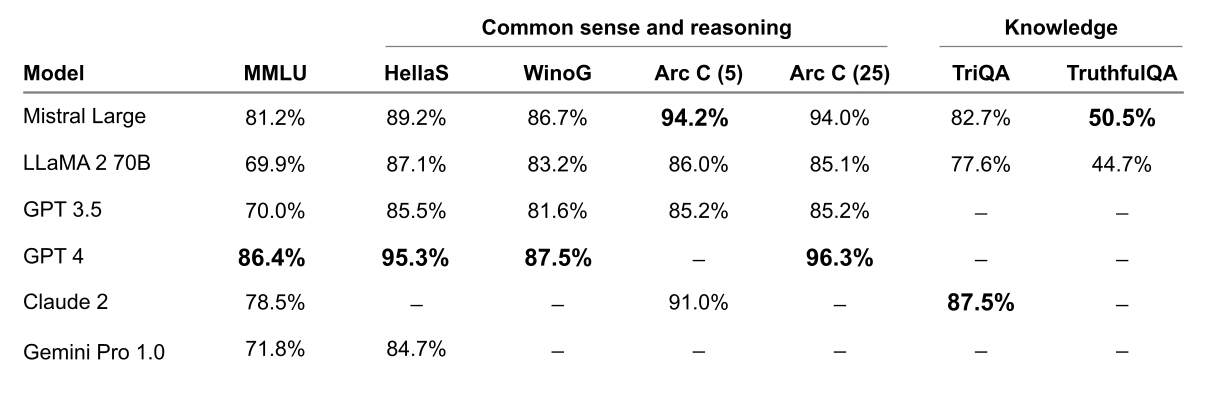
Figure 2: Performance on widespread common sense, reasoning and knowledge benchmarks of the top-leading LLM models on the market: MMLU (Measuring massive multitask language in understanding), HellaSwag (10-shot), Wino Grande (5-shot), Arc Challenge (5-shot), Arc Challenge (25-shot), TriviaQA (5-shot) and TruthfulQA.
Multi-lingual capacities
Mistral Large has native multi-lingual capacities. It strongly outperforms LLaMA 2 70B on HellaSwag, Arc Challenge and MMLU benchmarks in French, German, Spanish and Italian.
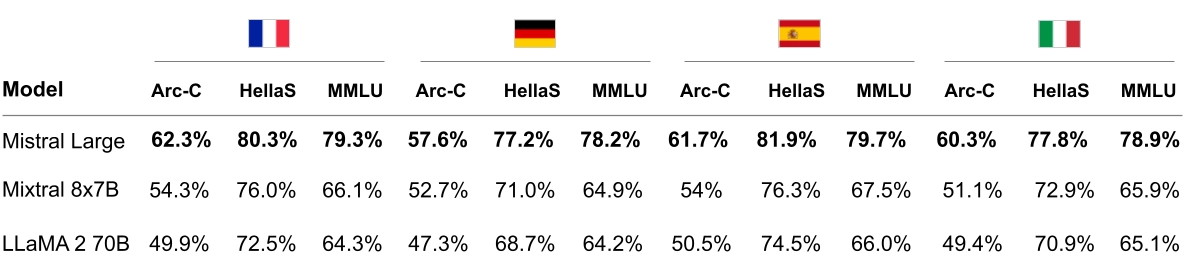
Figure 3: Comparison of Mistral Large, Mixtral 8x7B and LLaMA 2 70B on HellaSwag, Arc Challenge and MMLU in French, German, Spanish and Italian.
Maths & Coding
Mistral Large shows top performance in coding and math tasks. In the table below, we report the performance across a suite of popular benchmarks to evaluate the coding and math performance for some of the top-leading LLM models.
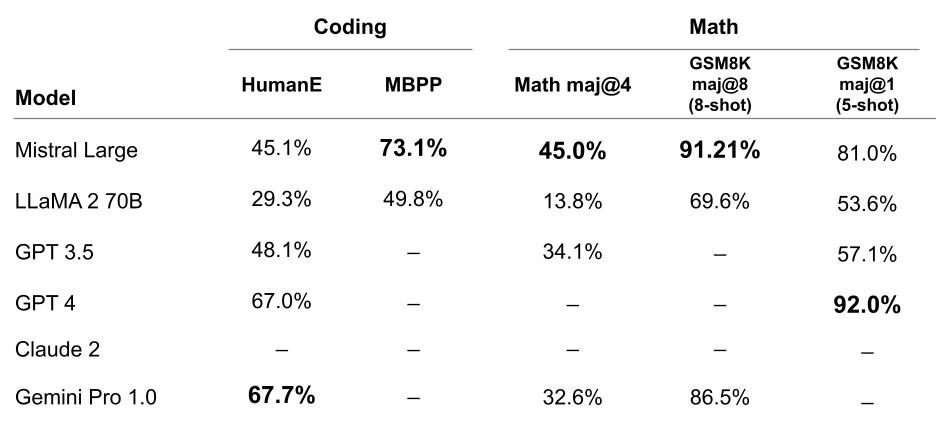
Figure 4: Performance on popular coding and math benchmarks of the leading LLM models on the market: HumanEval pass@1, MBPP pass@1, Math maj@4, GSM8K maj@8 (8-shot) and GSM8K maj@1 (5 shot).
A new Mistral Small, optimised for low latency workloads
Alongside Mistral Large, we're releasing a new optimised model, Mistral Small, optimised for latency and cost. Mistral Small outperforms Mixtral 8x7B and has lower latency, which makes it a refined intermediary solution between our open-weight offering and our flagship model.
Mistral Small benefits from the same innovation as Mistral Large regarding RAG-enablement and function calling.
We're simplifying our endpoint offering to provide the following:
Open-weight endpoints with competitive pricing. This comprises
open-mistral-7Bandopen-mixtral-8x7b.New optimised model endpoints,
mistral-small-2402andmistral-large-2402. We're maintainingmistral-medium, which we are not updating today.
Our benchmarks give a comprehensive view of performance/cost tradeoffs.
Beyond the new model offering, we're allowing organisation management multi-currency pricing and have updated service tiers on la Plateforme. We have also made a lot of progress in reducing the latency of all our endpoints.
JSON format and function calling
JSON format mode forces the language model output to be valid JSON. This functionality enables developers to interact with our models more naturally to extract information in a structured format that can be easily used in the remainder of their pipelines.
Function calling lets developers interface Mistral endpoints with a set of their own tools, enabling more complex interactions with internal code, APIs or databases. You will learn more in our function calling guide.
Function calling and JSON format are only available on mistral-small and mistral-large. We will be adding formatting to all endpoints shortly, as well as enabling more fine-grained format definitions.
Try Mistral Large and Mistral Small today
Mistral Large is available on la Plateforme and Azure as of today. Mistral Large is also exposed on our beta assistant demonstrator, le Chat. As always, we're eager to have your feedback!