Products
Compute
Il cloud per l'IA di frontiera.
Cluster di GPU dedicati. Velocità cloud-native. Massime prestazioni.


Progettato per i team di frontiera.
Progettiamo il futuro.
Aperto a laboratori di IA, team di ricerca e imprese che sviluppano per la frontiera.
Mistral Compute
Timeline
Test
Da zero al cloud in meno di un anno.

Capacità
200
MW
Capacità sovrana su scala frontiera in tutta l'UE, entro il 2027.
Ultima generazione NVIDIA
GPU: GB200 • GB300 • B300 CPU: Grace e x86
Cluster bare-metal su InfiniBand, strumentati dai nostri modelli.
Capacità sovrana in espansione in tutta Europa per soddisfare la crescente domanda di IA. Addestra, ottimizza e offri servizi con prestazioni eccezionali e la massima facilità d'uso.
A tua disposizione per costruire.
Prestazioni hardware dedicate con la flessibilità del cloud.
Accesso diretto all'hardware senza overhead di virtualizzazione. La velocità, la produttività e l'affidabilità che noi stessi vogliamo per l'addestramento dei nostri modelli di punta.
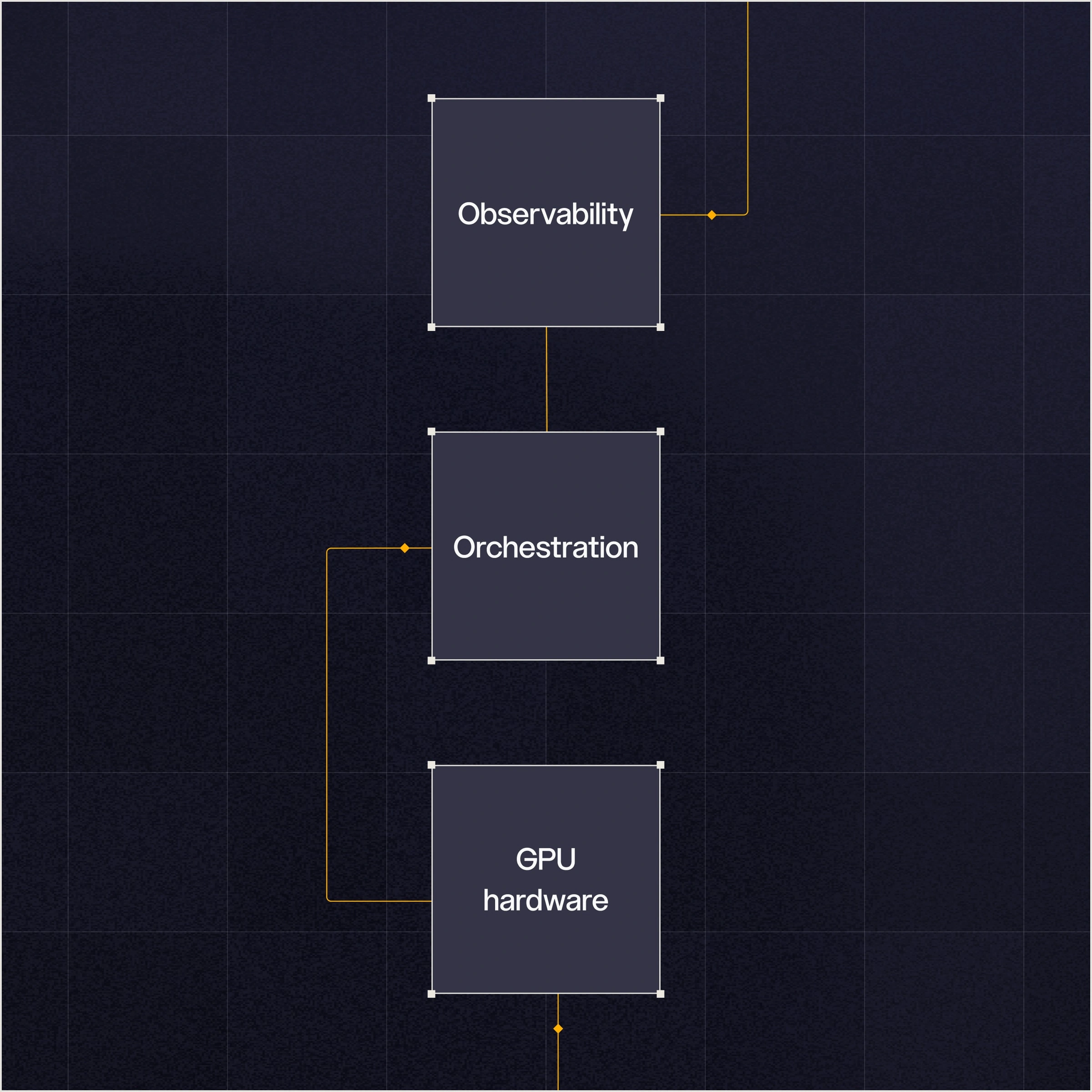
Provisioning e operazioni standardizzati. Il tuo hardware è gestito come se si trattasse di risorse Kubernetes-native. Multi-tenant in ogni aspetto della progettazione, con applicazione delle policy in tutti i cluster.
Progettato per i team di IA che eseguono processi di addestramento su vasta scala. Gestione delle code, livelli di priorità e condivisione equa tra i diversi team, con pianificazione sensibile alla topologia.
Built-in across every tier.

Osservabilità.
Dashboard, registri e metriche integrati. Nessun costo aggiuntivo. Stato della GPU, alimentazione, temperature, ECC, throughput. Telemetria per ogni processo, trasmessa in streaming agli strumenti che usi già.
Governance.
SSO e SCIM pronti all'uso. I controlli RBAC vengono mappati sugli account SLURM. Segreti, gestione delle chiavi, audit trail, webhook CI/CD.
Affidabilità.
SLA di livello enterprise per addestramento e inferenza, con risposta agli incidenti dedicata.
Assistenza.
Specialisti di infrastrutture e IA a ogni livello, con escalation diretta al team di progettazione della piattaforma. L'auto-riparazione è strumentata dai nostri modelli.
Sicurezza.
Sicurezza realizzata appositamente per carichi di lavoro di IA su larga scala: isolamento di rete EVPN-VXLAN, crittografia AES-256 dei dati inattivi con BYOK e protocollo di cancellazione dei dati definito.