-
Solutions
-
Speech
Intelligenza vocale che supera il test umano.
Sintesi vocale e trascrizione di frontiera per interazioni naturali, espressive e ricche di sfumature.
Voice agents
Text-to-speech

Speech-to-text
Basato su modelli vocali open source di ultima generazione.
Perché Mistral Speech?
Generazione e replica vocale che catturano personalità, ritmo e agilità emotiva.
Trascrizione che rimane accurata anche in condizioni reali e rumorose e che riconosce chi ha detto cosa.
Nove lingue per la generazione vocale, 13 per la trascrizione, con adattamento translinguistico e dialettale.

Modelli open‑weight, ottimizzazione per dominio e implementazione on‑premise. Controllo completo su ogni componente della pipeline.
Primi passi con Mistral Speech.
Chiudere il cerchio sull'intelligenza audio.
Crea e personalizza le voci.
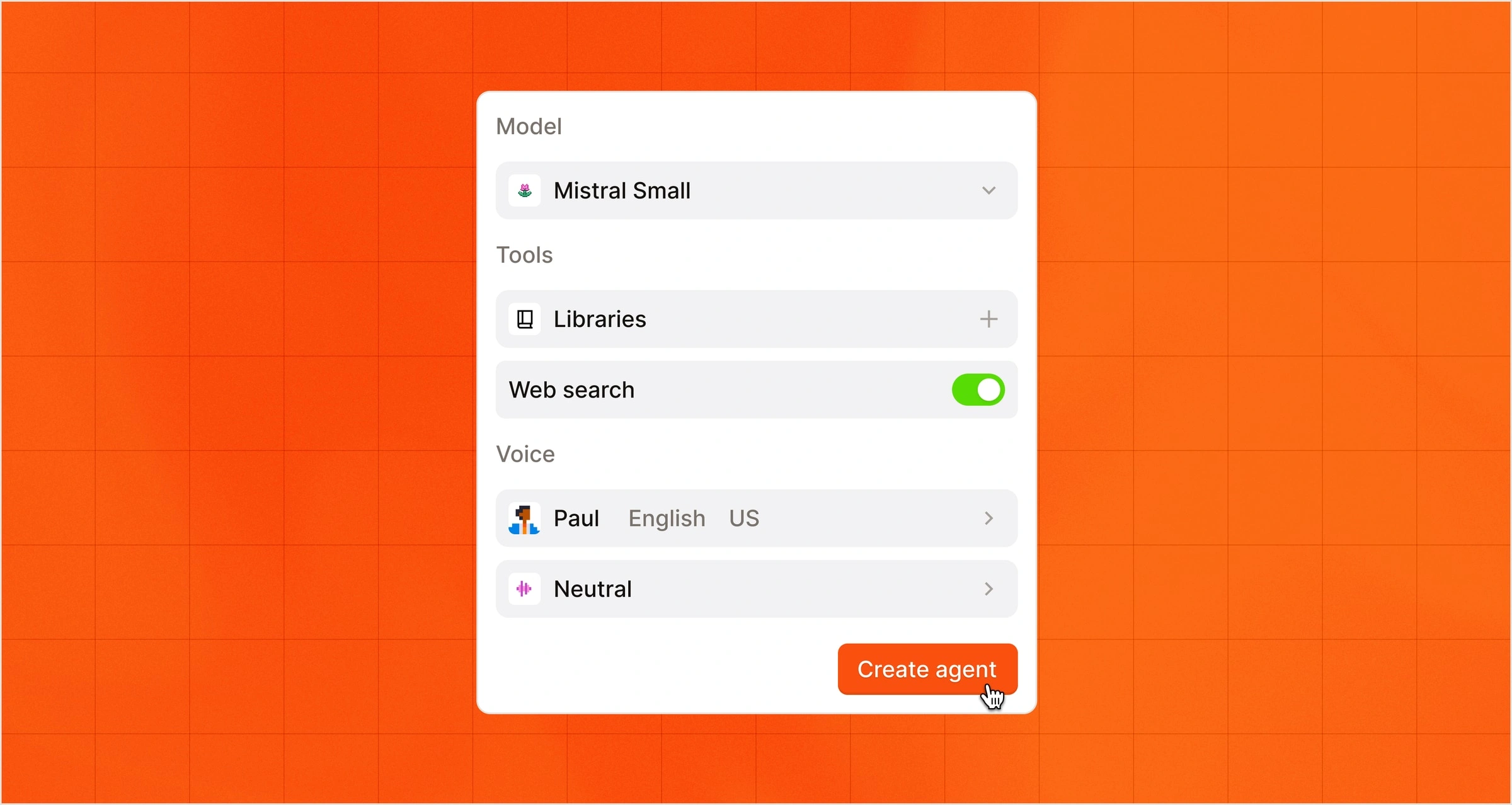
Agenti vocali.
Conversazioni vocali in tempo reale che ascoltano, ragionano e rispondono con la voce, il tono e le conoscenze di dominio del tuo brand.
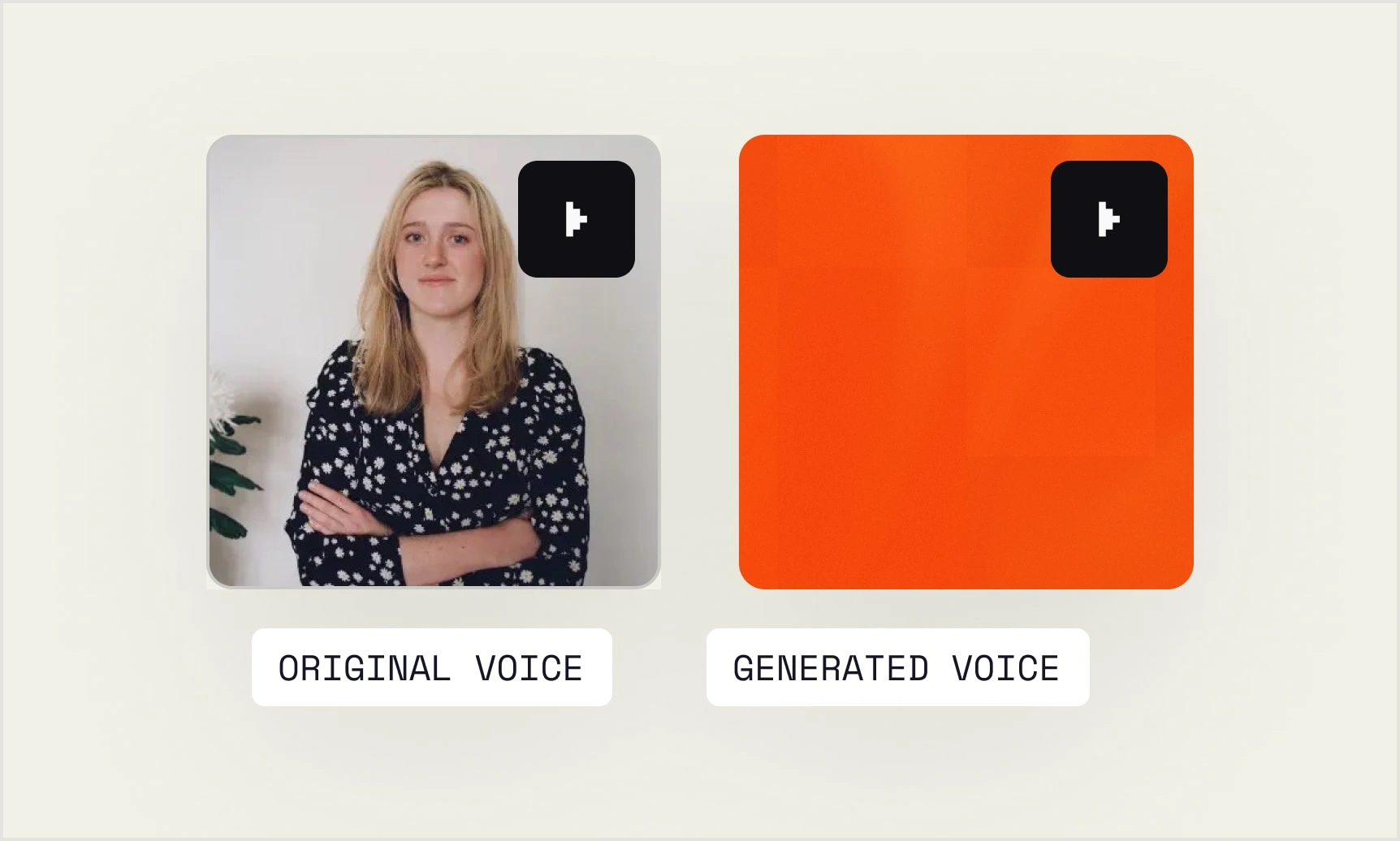
Clonazione vocale.
Replica qualsiasi voce a partire da un campione di appena 3 secondi, catturandone tono, ritmo e personalità.
Sintesi vocale.
Parlato emotivamente espressivo e clonazione vocale che catturano la personalità del parlante. Adattati a qualsiasi voce da un breve campione oppure usa voci preimpostate.
Cattura ogni parola.
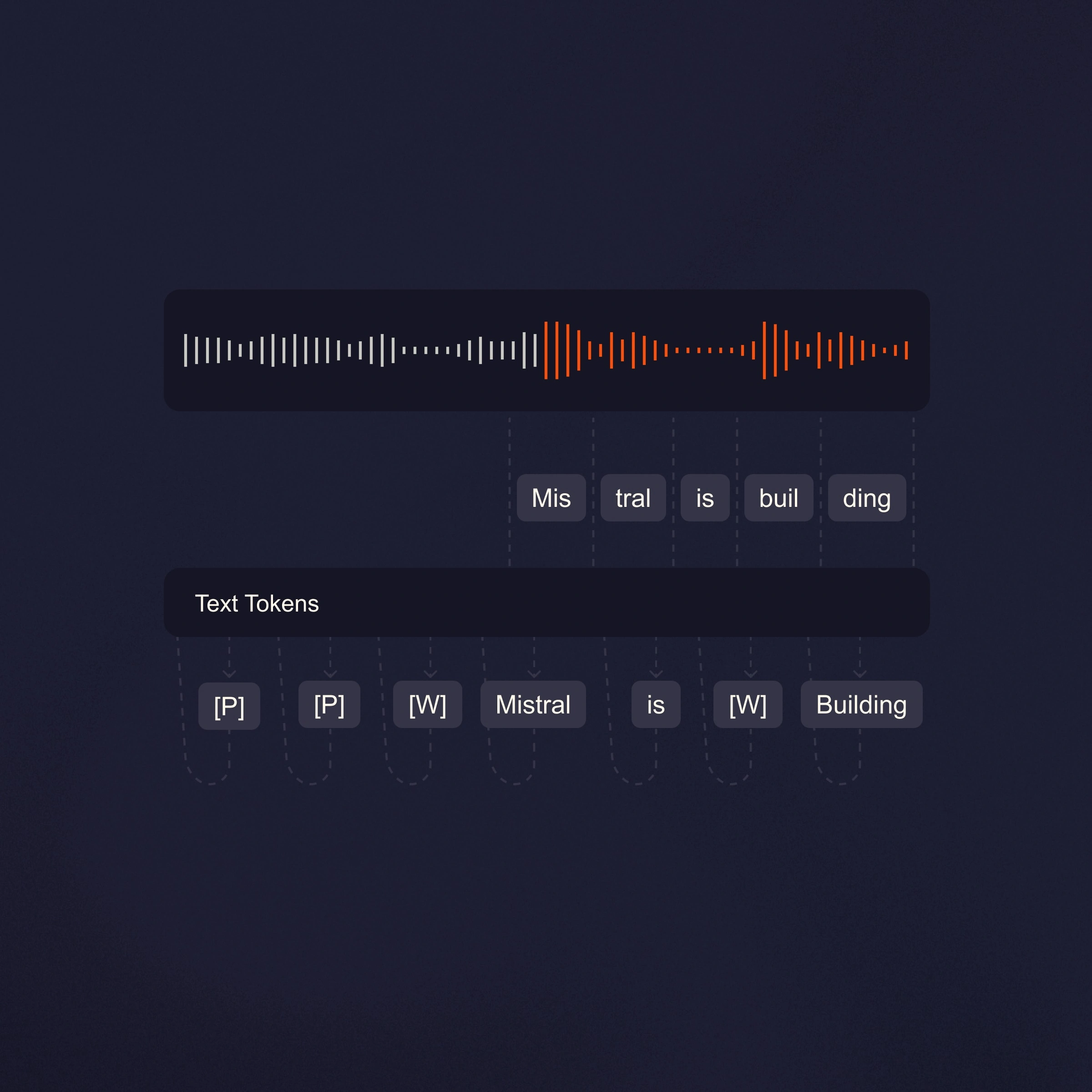
Trascrizione in tempo reale.
Architettura di streaming che trascrive l'audio man mano che arriva, non a blocchi, con una latenza configurabile fino a meno di 200 ms.
Trascrizione in blocco.
Elabora riunioni di molte ore, registrazioni di chiamate e archivi di conformità, con output strutturati e attribuzione dei parlanti.
Adattamento translinguistico.
Genera il parlato in una lingua utilizzando la voce di un'altra, preservandone accento e identità.
Prototipa, testa, ottimizza, adatta.
Ambiente audio.
Testa conversazioni, generazione vocale e trascrizione in Mistral Studio con attori vocali, emulazione vocale, diarizzazione e controlli per singolo input.
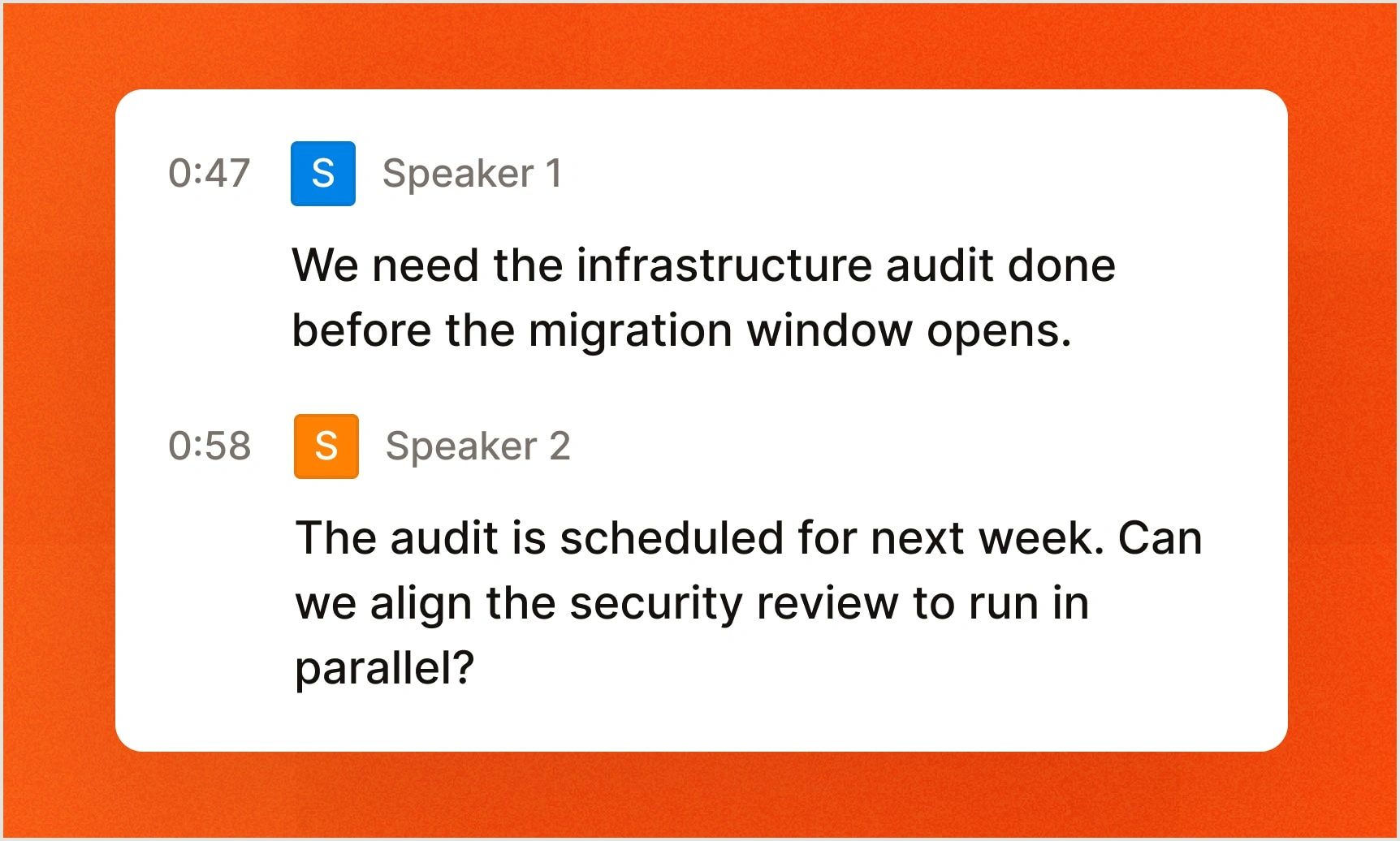
Diarizzazione dei parlanti.
Identifica chi ha detto cosa e quando, con etichette per ogni parlante e data e ora di inizio/fine per riunioni, interviste e chiamate con più partecipanti.
Ponderazione contestuale.
Guida il modello con fino a 100 termini personalizzati: nomi, vocabolario tecnico, gergo interno.

Come i team utilizzano Mistral Speech oggi.
Assistenza clienti.
Agenti vocali che instradano e risolvono le richieste su tutti i canali con un parlato naturale e coerente con il brand.
Servizi finanziari.
IA vocale conforme per la consulenza nella gestione patrimoniale, le richieste sulle polizze assicurative e l'onboarding dei clienti.
Operazioni manufatturiere e industriali.
Interfacce vocali per ispezioni della qualità, feedback sulla produzione e operazioni sul campo in ambienti ad alta rumorosità.
Servizi pubblici e pubblica amministrazione.
Assistenti vocali specifici per dialetto per i servizi ai cittadini, distribuiti su una infrastruttura sovrana.

Conformità e rischio.
Monitoraggio delle chiamate in tempo reale con attribuzione dei parlanti, automazione KYC/AML e registrazioni delle interazioni verificabili.
Catena di fornitura e logistica.
Tracciamento delle spedizioni con supporto vocale, coordinamento doganale e gestione delle eccezioni in più lingue.
Sistemi automobilistici e di bordo.
Modelli leggeri on-device che alimentano interfacce vocali senza dipendenza dal cloud.
Vendite e marketing.
Intelligenza per le riunioni con attribuzione dei parlanti, analisi della pipeline e follow-up automatizzati.
Traduzione in tempo reale.
Adattamento vocale multilingue per la traduzione in tempo reale, conservando l'identità e l'accento del parlante.
Risorse.
Domande frequenti.
Prova la generazione e la trascrizione vocale nell'ambiente audio di Mistral Studio, integra tramite API o scarica i modelli open‑weight per l'hosting autonomo.
Sì, due. Voxtral Mini Transcribe 2 per la trascrizione in blocco con diarizzazione dei parlanti e ponderazione contestuale e Voxtral Realtime per la trascrizione in live streaming con latenza inferiore a 200 ms.
Sì, puoi fornire un campione vocale anche di soli 3 secondi e Voxtral TTS, il nostro modello di sintesi vocale, si adatterà per catturare il tono, il ritmo e la personalità del parlante. Puoi anche usare voci preimpostate o creare la tua libreria vocale.
La trascrizione supporta 13 lingue, tra cui inglese, francese, tedesco, spagnolo, cinese, hindi, arabo, portoghese, russo, giapponese, coreano, italiano e olandese.
La generazione vocale supporta 9 lingue con espressioni dialettali in inglese, francese, tedesco, spagnolo, olandese, portoghese, italiano, hindi e arabo.
Un esempio di combinazione di modelli Voxtral per formare una pipeline speech-to-speech è:
Voxtral Realtime trascrive il parlato in ingresso, un altro Mistral LLM elabora la trascrizione e determina una risposta, e Voxtral TTS genera l'output vocale.
Ogni componente è personalizzabile e distribuibile in modo indipendente.
L'adattamento vocale multilingue significa che la pipeline può gestire anche la traduzione in tempo reale preservando accento e identità del parlante.
Sì, puoi eseguire in hosting autonomo Mistral Speech o distribuirlo su Mistral Compute.