


-
Solutions
-
Custom model training
Intelligence tailored to your domain. Developed together.

Build domain-specialized AI with Mistral.
Collaborative model customization.
Work with Mistral experts to tune frontier models using your proprietary data. Create domain-specialized LLMs tailored to your most critical use cases across industries like finance, healthcare, manufacturing, and more.
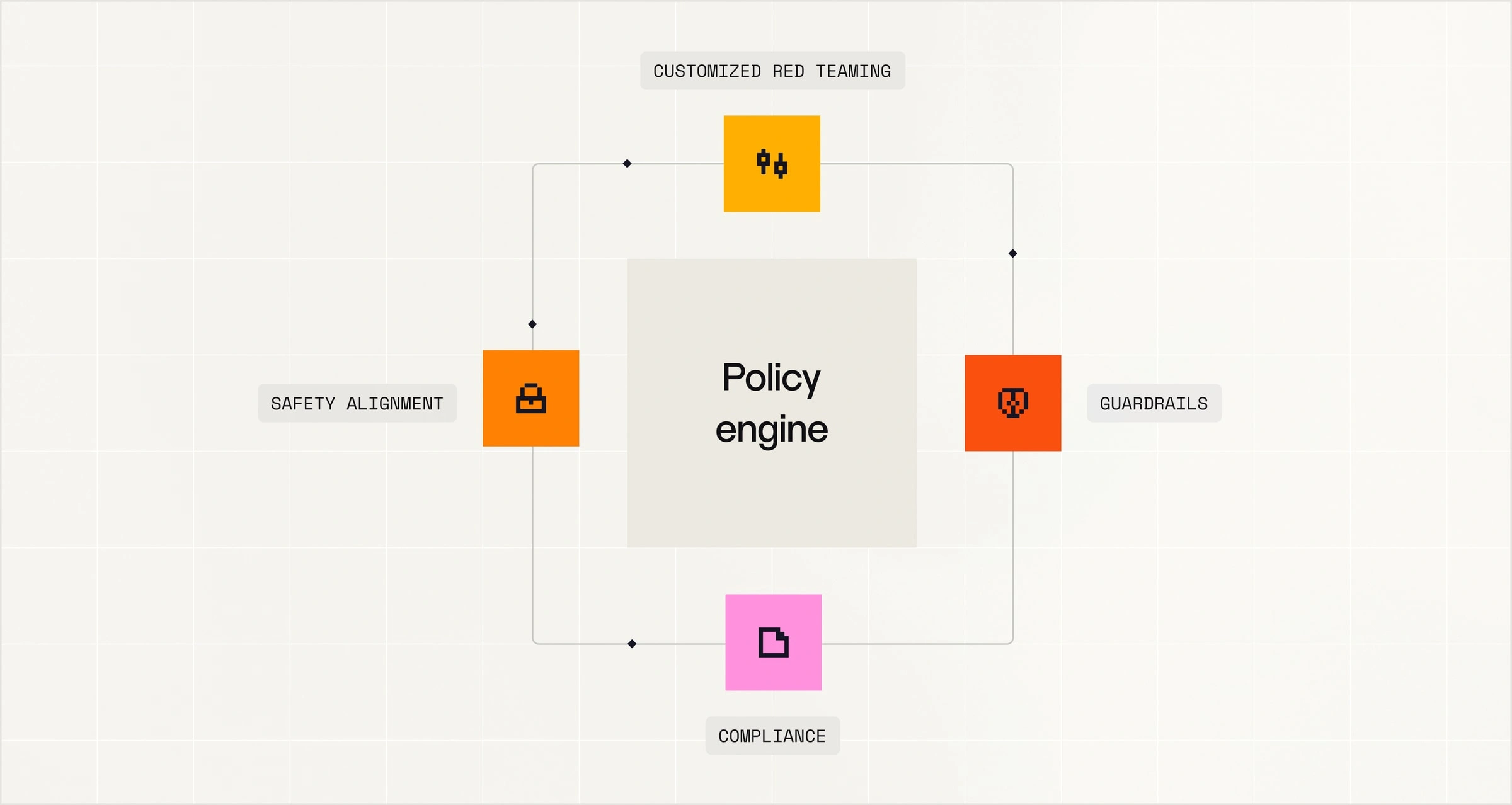
Fully-owned AI for your data and compliance needs.
Combine your data with Mistral’s proven models, recipes, and tools to build specialized frontier models quickly, reliably, and under your full control. Ensure privacy, security, and compliance with sovereign boundaries, strict data isolation, and audit-ready governance.
Trainable anywhere, deployable everywhere.
Deploy models anywhere: on-prem, in the cloud, or on-device with optimized infrastructure. Co-build AI centers of excellence to foster long-term independence and expertise.
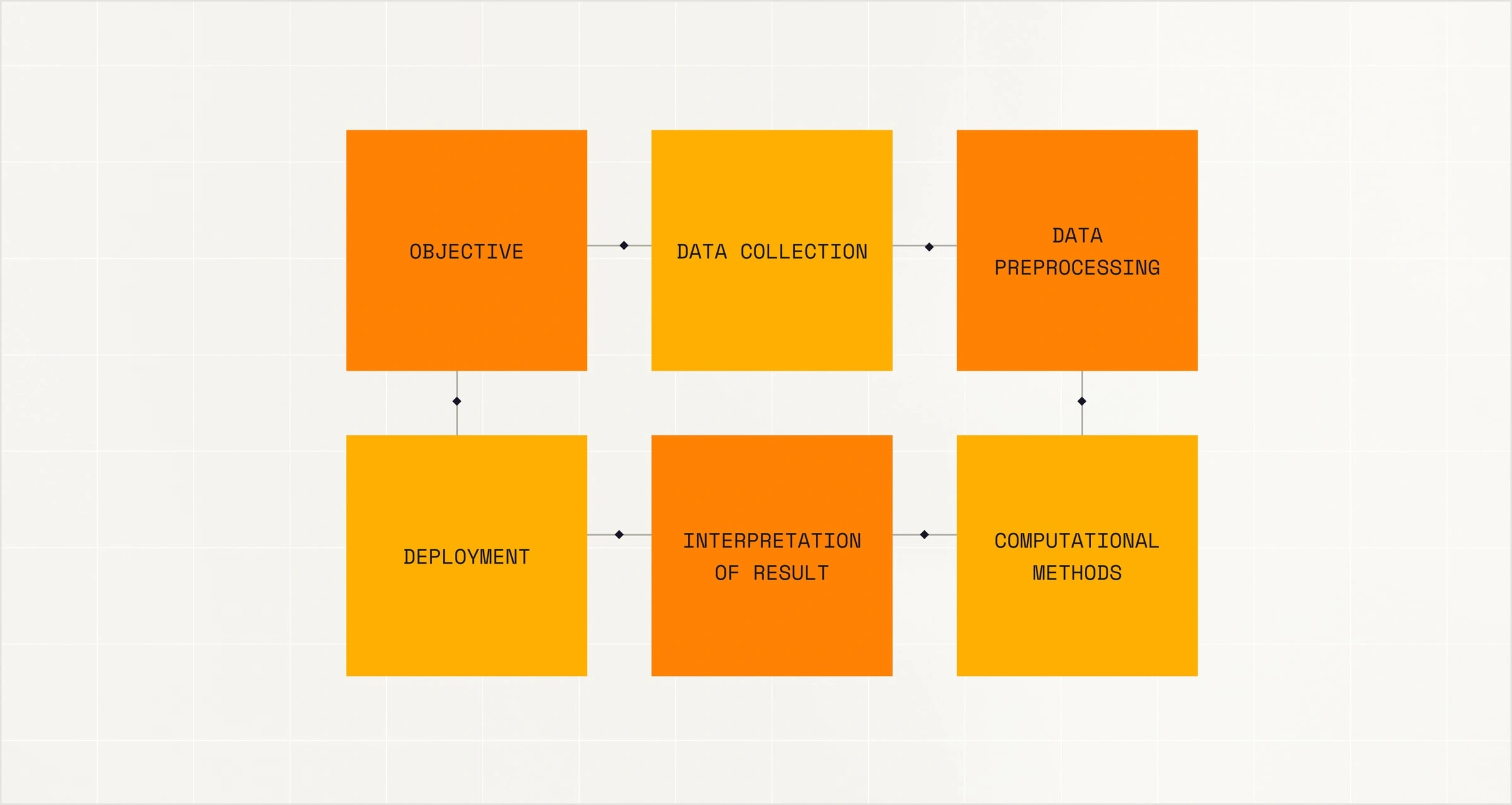
Frontier model customization, from fine-tuning to full pre-training.
Partner with Mistral to build, align, and evolve models using the same methods that power our frontier systems. Every stage—from pre-training to post-training and fine-tuning—ensures domain specialization, sovereignty, and flexible deployment.
Domain knowledge integration.
Extend foundational models with your proprietary data and domain expertise to create true domain specialists.
Behavior and policy alignment.
Shape model cognition with human and synthetic feedback to align with your operational and organizational parameters.
Computational optimization.
Engineer for deterministic, high-throughput operation to push performance to the limits of your hardware.
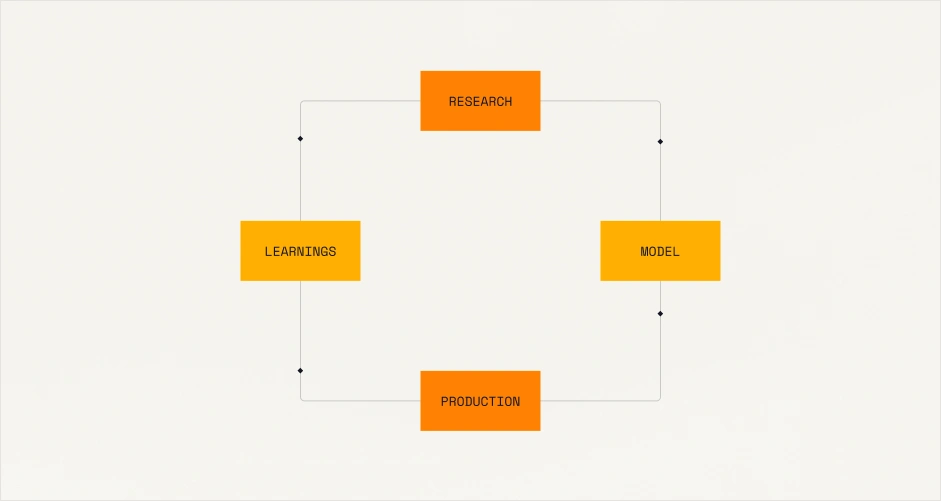
Continuous reinforcement.
Close the loop between production and research to refine and harden model robustness over time.
Level up your AI initiatives.
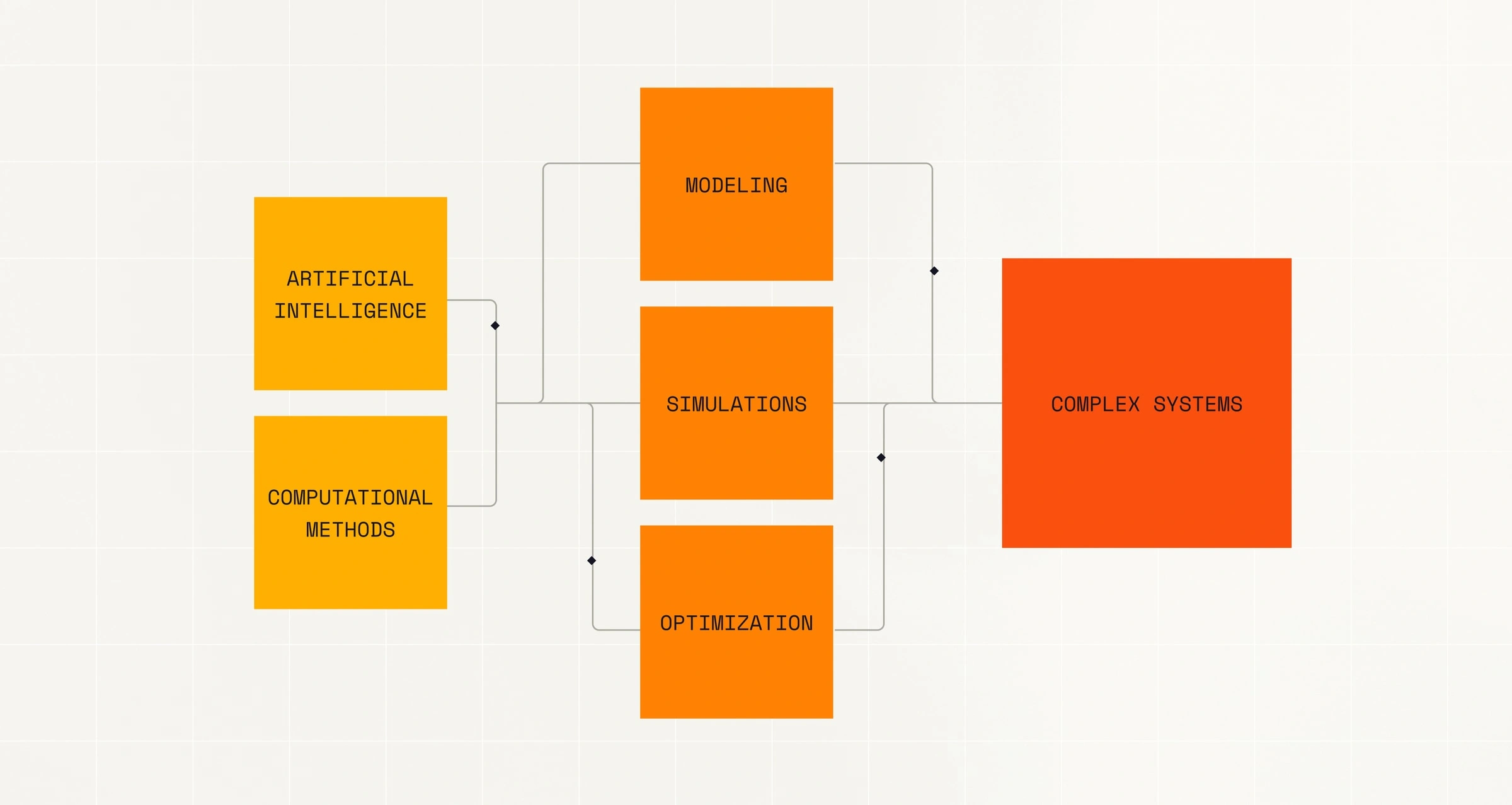
Mission-critical intelligence.
Build models that make high-impact decisions under uncertainty—detecting fraud, predicting failures, and managing systemic risk at scale.
Domain-deep modeling.
Engineer expert systems that internalize the complexity of advanced fields—from materials science and finance to seismology and aerospace.

Planet-scale operations.
Deploy models that orchestrate vast, interdependent systems—optimizing logistics, energy networks, and infrastructure in real time.
Frontier research.
Push beyond established architectures to design and train new foundation models, exploring emergent reasoning and multimodal understanding.
High-performance deployment.
Run dense inference and fine-tuning workloads on-prem or at the edge, with strict control over latency, efficiency, and data sovereignty.
Full-stack capability building.
Enable your teams to train, scale, and operate large models end-to-end, leveraging the same production-proven systems behind Mistral’s breakthroughs.
Helping companies solve the world’s most difficult problems.
The collaboration between Mistral AI and ASML aims to generate clear benefits for ASML customers through innovative products and solutions enabled by AI, and will offer potential for joint research to address future opportunities. We believe that this strategic partnership with Mistral AI, which goes beyond a traditional vendor-client relationship, is the best way to capture this significant opportunity.

Helsing and Mistral AI have formed a strategic partnership to develop next-generation AI systems for European defence. This collaboration focuses on Vision-Language-Action models, enhancing defence platforms' ability to understand their environment, communicate with operators, and make rapid, reliable decisions in complex scenarios.
With the help of Mistral, HTX is fine-tuning pretrained models and also building their own series of LLMs, codenamed Phoenix. Phoenix has been pre-trained on extensive corpuses of knowledge specific and relevant to the Home Team and Singapore, as well as 10 major languages spoken in Singapore—including Mandarin, Bahasa Melayu, and Tamil. This will allow Home team officers to get more accurate responses compared to other kinds of LLMs.