Products
Compute
Le cloud d'IA de pointe.
Clusters GPU dédiés. Vitesse native du cloud. Performances optimales.


Conçu pour les équipes de pointe.
Construisez l'avenir.
Ouvert aux laboratoires d'IA, aux équipes de recherche et aux entreprises qui développent à grande échelle.
Mistral Compute
Timeline
Test
Passez au cloud en moins d'un an.

Capacité
200
MW
Une capacité souveraine à l'échelle frontalière dans toute l'UE, d'ici 2027.
Dernière génération NVIDIA
GPU : GB200 • GB300 • B300 CPU : Grace et x86
Clusters bare-metal sur InfiniBand, instrumentés par nos propres modèles.
La capacité souveraine s'étend à travers l'Europe pour répondre à la demande croissante en matière d'IA. Entraînez, ajustez et déployez vos modèles en alliant performances brutes et simplicité d'utilisation.
À vous de construire.
Des performances matérielles dédiées avec la flexibilité du cloud.
Accès direct au matériel sans surcharge liée à la virtualisation. La vitesse, le débit et la fiabilité que nous exigeons pour notre propre formation phare.
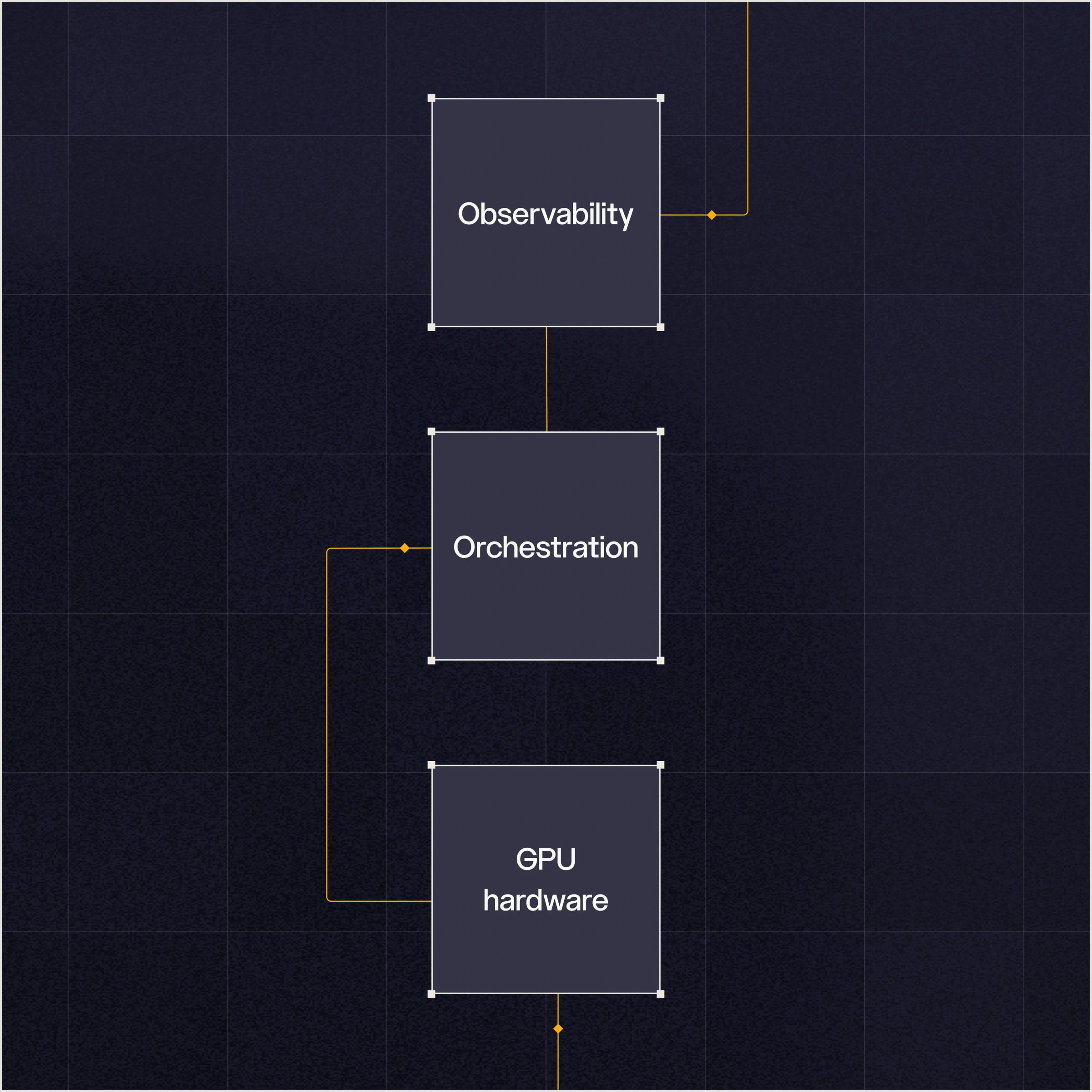
Provisionnement et opérations standardisés. Votre matériel est géré comme des ressources Kubernetes natives. Conçu pour le multi-tenant, avec application des politiques sur chaque cluster.
Conçu pour les équipes d'IA qui exécutent des tâches d'entraînement à grande échelle. Gestion des files d'attente, niveaux de priorité et répartition équitable entre les équipes, avec planification tenant compte de la topologie.
Built-in across every tier.

Observabilité.
Tableaux de bord, journaux et indicateurs intégrés. Sans frais supplémentaires. Intégrité des GPU, consommation électrique, température, ECC, débit. Télémétrie par tâche, transmise en continu aux outils que vous utilisez déjà.
Gouvernance.
SSO et SCIM prêts à l'emploi. RBAC correspondant aux comptes SLURM. Secrets, gestion des clés, pistes d'audit, webhooks CI/CD.
Fiabilité.
SLA de niveau entreprise pour l'entraînement et l'inférence, avec une réponse dédiée aux incidents.
Assistance.
Spécialistes en infrastructure et en IA à tous les niveaux, avec escalade directe vers l'équipe d'ingénieurs responsable de la plateforme. La réparation automatique est mise en œuvre par nos propres modèles.
Sécurité.
Sécurité spécialement conçue pour les charges de travail IA à grande échelle : Isolation réseau EVPN-VXLAN, chiffrement AES-256 au repos avec BYOK et protocole défini d'effacement des données.