Solutions
Speech
Une intelligence vocale qui réussit le test humain.
Transcription, synthèse vocale et agents vocaux de pointe pour des interactions naturelles, expressives et nuancées avec l'IA vocale.
Trois solutions fondamentales d'IA vocale pour toutes les conversations.
Voice agents
Text-to-speech

Speech-to-text
Pourquoi utiliser Mistral Speech ?
Une synthèse et une reproduction vocales qui restituent la personnalité, le rythme et la nuance émotionnelle.
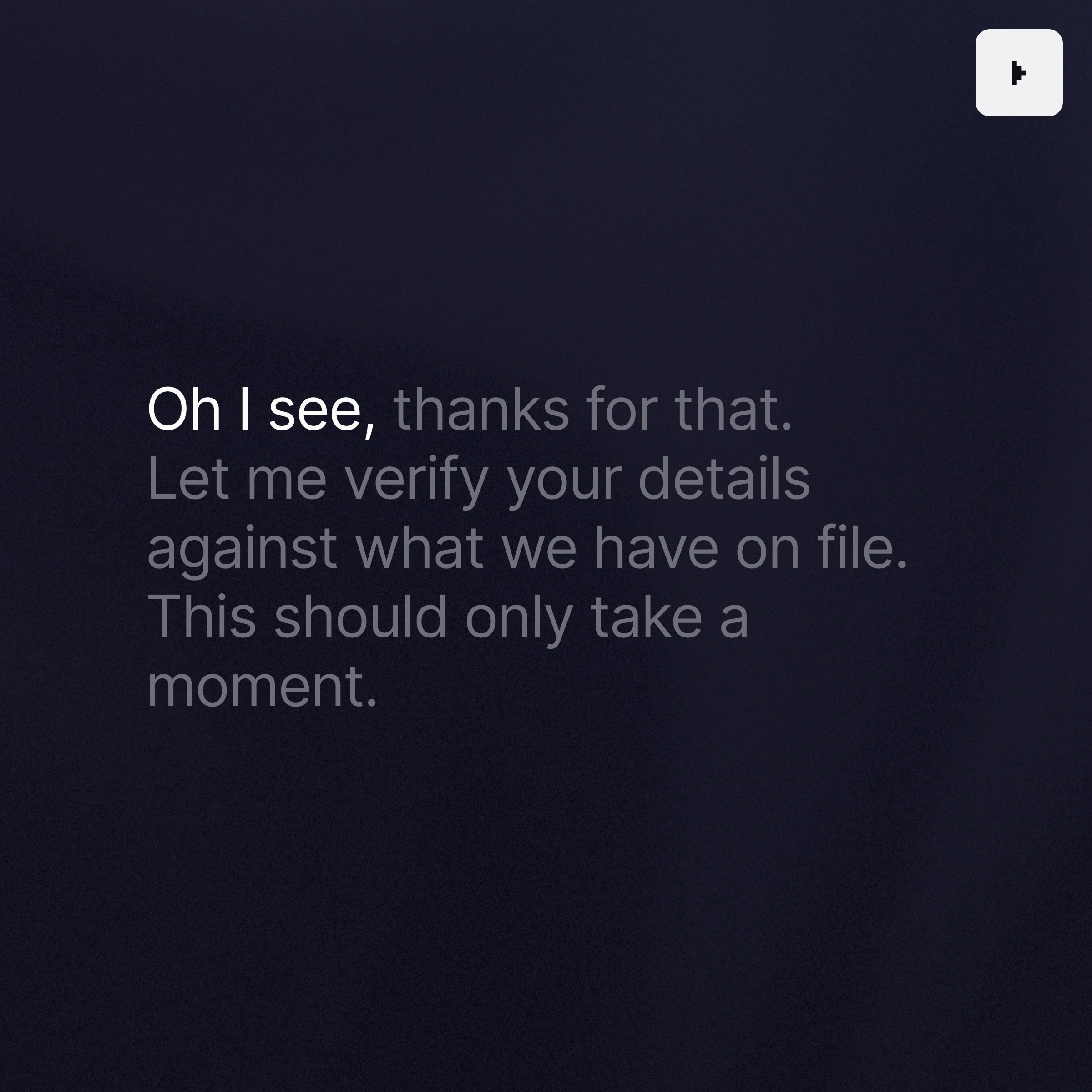
Une transcription précise dans des conditions réelles et bruyantes, qui identifie avec exactitude les locuteurs et leurs propos.
Neuf langues pour la synthèse vocale, treize pour la transcription, avec adaptation interlinguistique et dialectale.

Open-weights, ajustement du domaine et déploiement sur site. Contrôle total de chaque composant du pipeline.
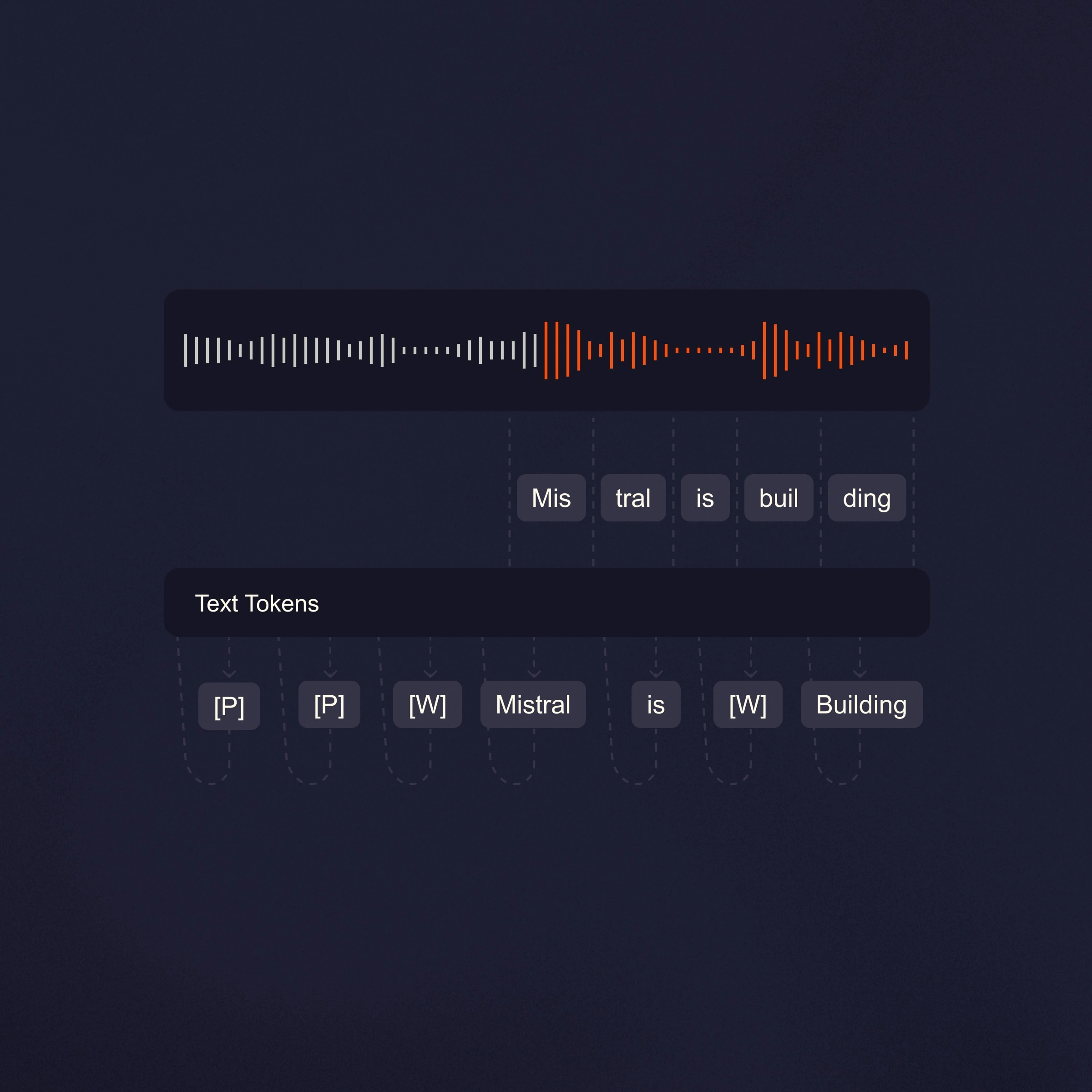
Comment les équipes utilisent Mistral Speech aujourd'hui.
Par cas d'utilisation.
Le service client.
Des agents vocaux acheminent et traitent les requêtes sur tous les canaux en utilisant un langage naturel et adapté à l'image de marque.

La conformité et les risques.
Une surveillance des appels en temps réel avec l'identification des locuteurs, l'automatisation KYC/AML et l'enregistrement d'interactions pouvant faire l'objet d'un audit.
La chaîne d'approvisionnement et la logistique.
Un suivi des expéditions, une coordination douanière et une gestion des exceptions par commande vocale, dans toutes les langues.
La vente et le marketing.
Des informations sur les réunions avec l'identification des locuteurs, l'analyse du pipeline et le suivi automatisé.
Traduction en temps réel.
Adaptation vocale multilingue pour la traduction en direct, en préservant l'identité et l'accent du locuteur.
Par secteur.
Financial services.
Compliant voice AI for wealth management advisory, insurance policy queries, and client onboarding.
Manufacturing and industrial operations.
Voice interfaces for quality inspection, production feedback, and field operations in high-noise environments.
Public services and government.
Dialect-specific voice assistants for citizen services, deployed on sovereign infrastructure.
Automotive and in-vehicle systems.
Lightweight on-device models powering voice interfaces without cloud dependency.
Boucler la boucle de l'intelligence audio.
Agents vocaux.
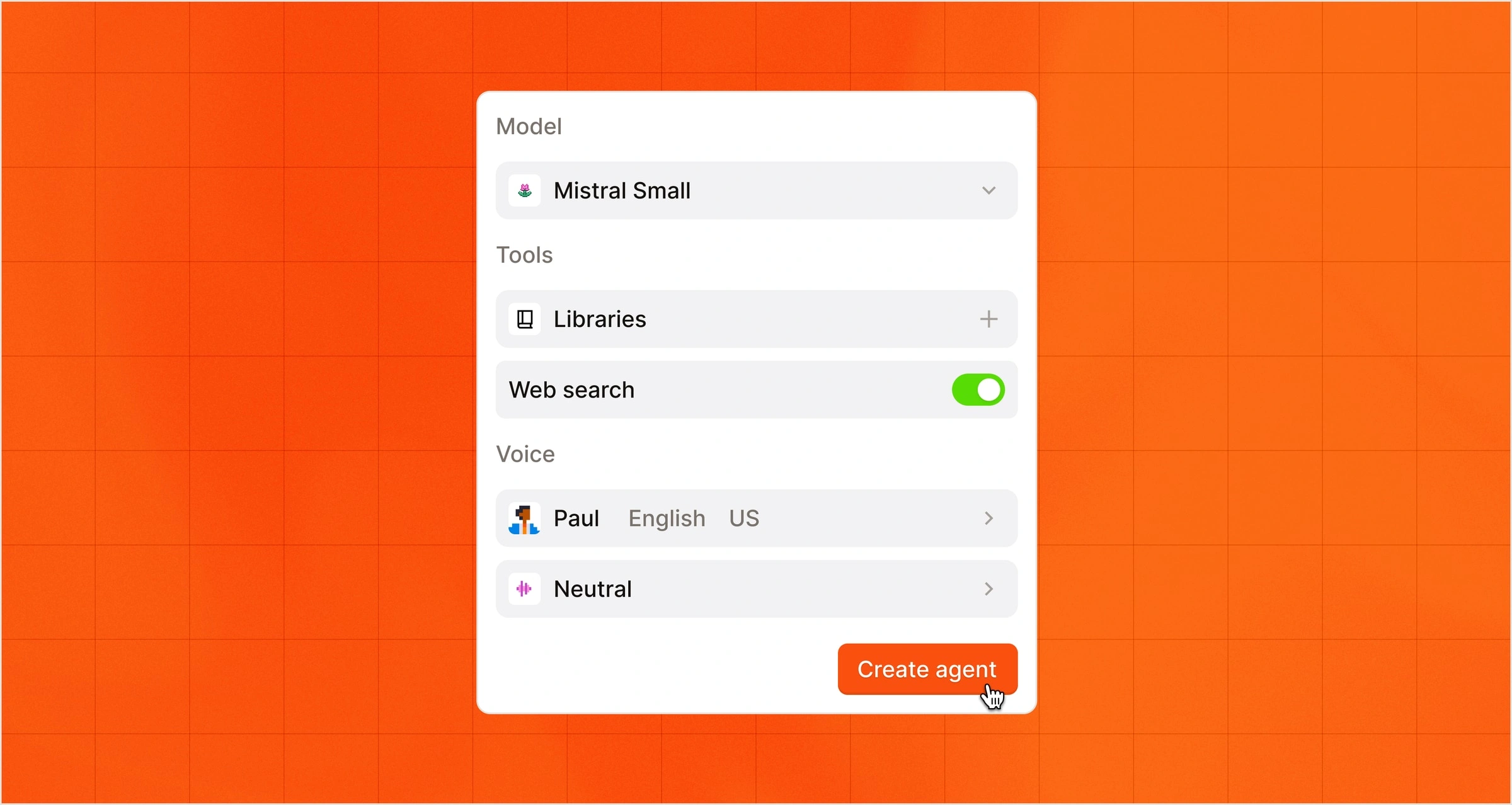
Parlez et faites-vous entendre.
Des conversations vocales en temps réel qui écoutent, raisonnent et répondent en adoptant le style, le ton et les connaissances spécifiques de votre marque.
Prenez ce dont vous avez besoin.
Des solutions composables que vous pouvez exécuter de bout en bout ou intégrer à votre stack STT et LLM.
Synthèse vocale.
Trouvez votre voix.
Une élocution riche en émotions qui reflète la personnalité du locuteur. Choisissez parmi les voix prédéfinies ou créez la vôtre.
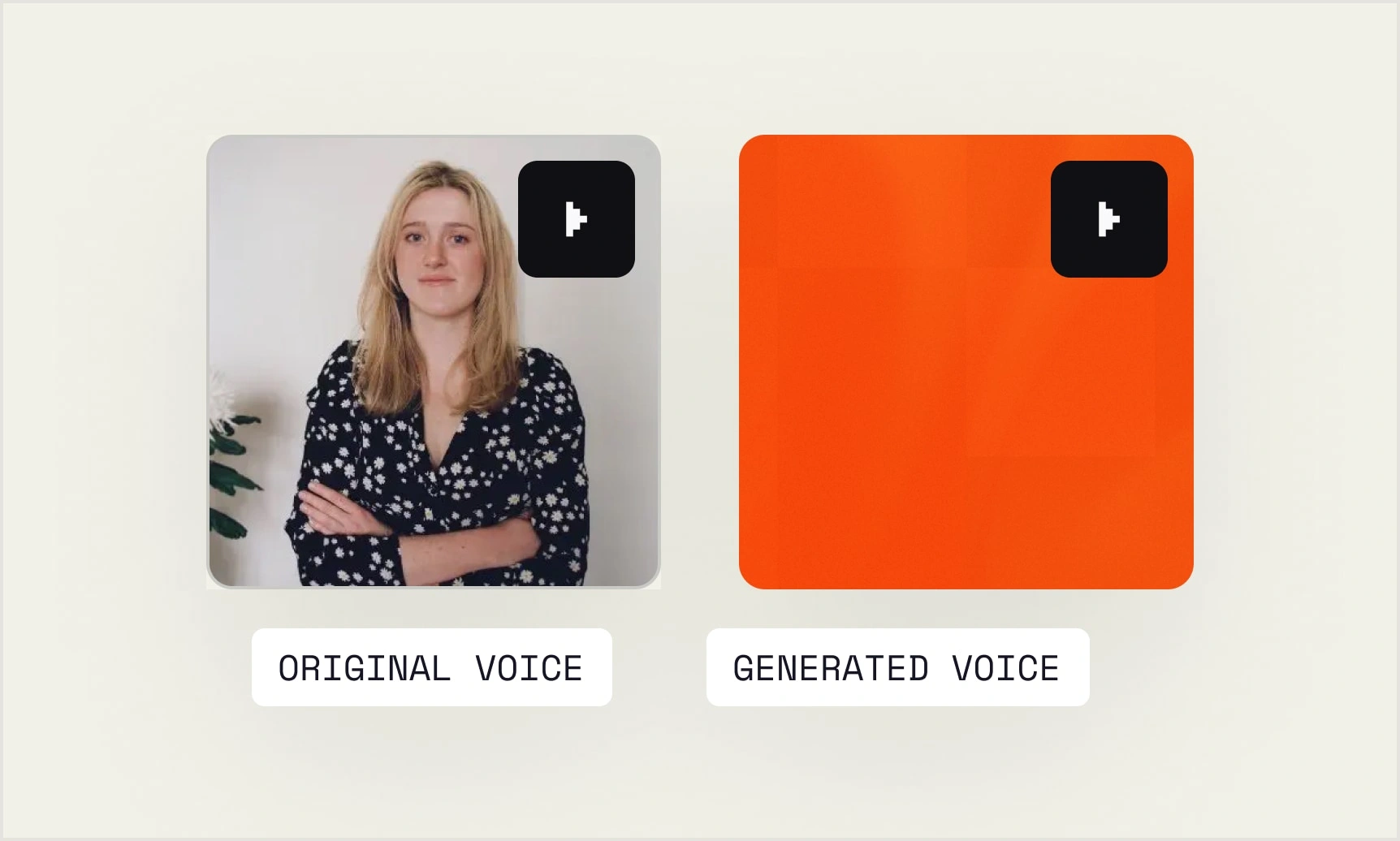
Clonage de la voix.
Répliquez n'importe quelle voix d'un échantillon en seulement 3 secondes, en capturant le ton, le rythme et la personnalité. Générez un discours dans une langue que le locuteur n'a jamais parlée, tout en conservant son accent et son identité.
Reconnaissance vocale.
Diffusez en direct ou envoyez.
Transcription en temps réel avec une latence inférieure à 200 ms, ou transcription par lots d'enregistrements de plusieurs heures avec des résultats structurés.
Des transcriptions qui comprennent.
La diarisation des locuteurs capture qui a dit quoi, avec des horodatages. Les biais contextuels prennent en charge jusqu'à 100 termes personnalisés, ce qui lui permet de comprendre votre langage.
Découvrir Mistral Speech.
Foire aux questions.
Essayez la synthèse vocale et la transcription dans l'Audio Playground de Mistral Studio, intégrez ces fonctionnalités via l'API ou téléchargez les open-weights pour les auto-héberger.
Oui, deux. Voxtral Mini Transcribe 2 pour la transcription par lots avec la diarisation des locuteurs et la prise en compte des biais contextuels et Voxtral Realtime pour la transcription en direct avec une latence inférieure à 200 ms.
Oui, vous pouvez fournir un échantillon de voix de seulement 3 secondes et Voxtral TTS, notre modèle de synthèse vocale, s'adaptera pour capturer le ton, le rythme et la personnalité du locuteur. Vous pouvez également utiliser des voix prédéfinies ou créer votre propre bibliothèque vocale.
La transcription prend en charge 13 langues, dont l'anglais, le français, l'allemand, l'espagnol, le chinois, l'hindi, l'arabe, le portugais, le russe, le japonais, le coréen, l'italien et le néerlandais.
La synthèse vocale prend en charge 9 langues et propose des expressions idiomatiques en anglais, français, allemand, espagnol, néerlandais, portugais, italien, hindi et arabe.
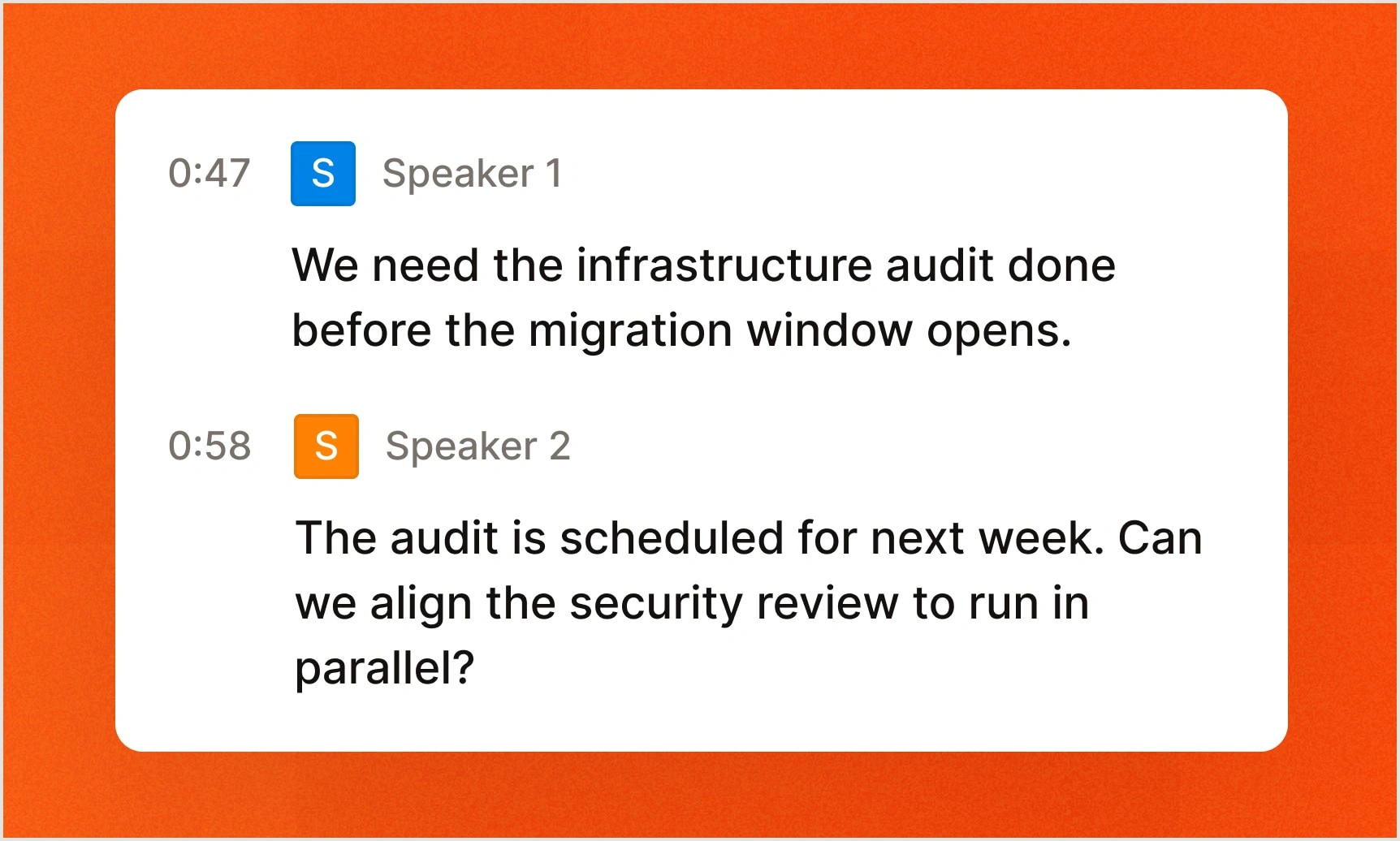
Voici un exemple de combinaison de modèles Voxtral pour former un pipeline de parole à parole :
Voxtral Realtime transcrit la parole entrante, un autre modèle de langage Mistral analyse la transcription et détermine une réponse, puis Voxtral TTS génère la sortie vocale.
Chaque composant peut être personnalisé et déployé indépendamment.
L'adaptation vocale interlinguistique signifie que le pipeline peut également gérer la traduction simultanée tout en préservant l'accent et l'identité du locuteur.
Oui, vous pouvez auto-héberger Mistral Speech ou le déployer sur Mistral Compute.