



Heads up: this model is deprecated
Mistral OCR is no longer maintained and has been replaced by our latest, more powerful OCR models.
Throughout history, advancements in information abstraction and retrieval have driven human progress. From hieroglyphs to papyri, the printing press to digitization, each leap has made human knowledge more accessible and actionable, fueling further innovation.
Today, we’re at the precipice of the next big leap—to unlock the collective intelligence of all digitized information. Approximately 90% of the world’s organizational data is stored as documents, and to harness this potential, we are introducing Mistral OCR.
Mistral OCR is an Optical Character Recognition API that sets a new standard in document understanding. Unlike other models, Mistral OCR comprehends each element of documents—media, text, tables, equations—with unprecedented accuracy and cognition. It takes images and PDFs as input and extracts content in an ordered interleaved text and images.
As a result, Mistral OCR is an ideal model to use in combination with a RAG system taking multimodal documents (such as slides or complex PDFs) as input.
We have made Mistral OCR as the default model for document understanding across millions of users on Le Chat, and are releasing the API mistral-ocr-latest at 1000 pages / $ (and approximately double the pages per dollar with batch inference). The API is available today on our developer suite la Plateforme, and coming soon to our cloud and inference partners, as well as on-premises.
Highlights
State of the art understanding of complex documents
Natively multilingual and multimodal
Top-tier benchmarks
Fastest in its category
Doc-as-prompt, structured output
Selectively available to self-host for organizations dealing with highly sensitive or classified information
Let’s dive into each.
State of the art understanding of complex documents
Mistral OCR excels in understanding complex document elements, including interleaved imagery, mathematical expressions, tables, and advanced layouts such as LaTeX formatting. The model enables deeper understanding of rich documents such as scientific papers with charts, graphs, equations and figures.
Below is an example of the model extracting text as well as imagery from a given PDF into a markdown file. You can access the notebook here.
Below we have side-by-side comparisons of PDFs and their respective OCR's outputs. Hover the slider to switch between input and output.
Tables + Figures

OCR result
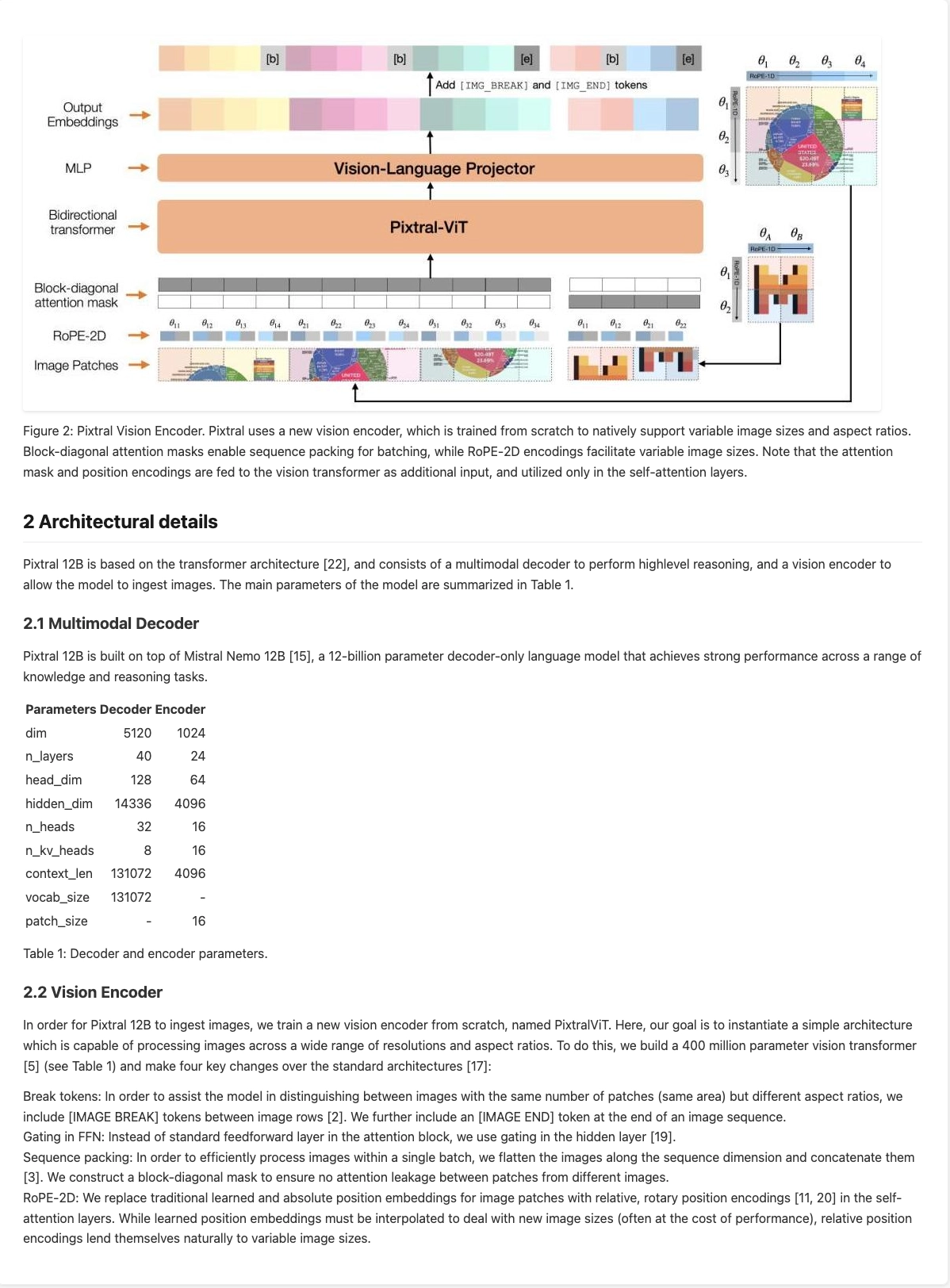
Math

OCR result

Hindi

OCR result
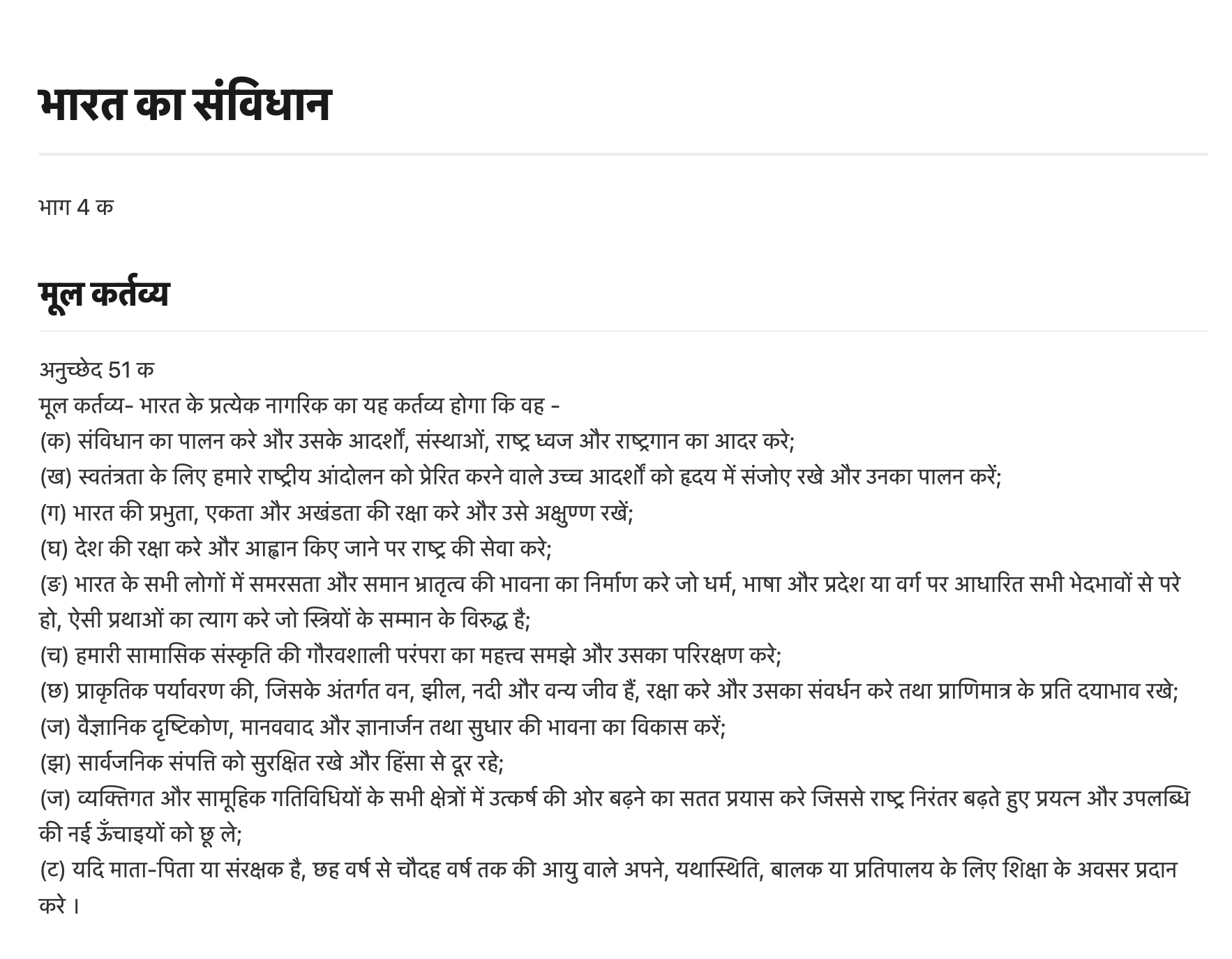
Document

OCR result

Arabic

OCR result

Top-tier benchmarks
Mistral OCR has consistently outperformed other leading OCR models in rigorous benchmark tests. Its superior accuracy across multiple aspects of document analysis is illustrated below. We extract embedded images from documents along with text. The other LLMs compared below, do not have that capability. For a fair comparison, we evaluate them on our internal “text-only” test-set containing various publication papers, and PDFs from the web; below:
Model | Overall | Math | Multilingual | Scanned | Tables |
|---|---|---|---|---|---|
Google Document AI | 83.42 | 80.29 | 86.42 | 92.77 | 78.16 |
Azure OCR | 89.52 | 85.72 | 87.52 | 94.65 | 89.52 |
Gemini-1.5-Flash-002 | 90.23 | 89.11 | 86.76 | 94.87 | 90.48 |
Gemini-1.5-Pro-002 | 89.92 | 88.48 | 86.33 | 96.15 | 89.71 |
Gemini-2.0-Flash-001 | 88.69 | 84.18 | 85.80 | 95.11 | 91.46 |
GPT-4o-2024-11-20 | 89.77 | 87.55 | 86.00 | 94.58 | 91.70 |
Mistral OCR 2503 | 94.89 | 94.29 | 89.55 | 98.96 | 96.12 |
Natively multilingual
Since Mistral’s founding, we have aspired to serve the world with our models, and consequently strived for multilingual capabilities across our offerings. Mistral OCR takes this to a new level, being able to parse, understand, and transcribe thousands of scripts, fonts, and languages across all continents. This versatility is crucial for both global organizations that handle documents from diverse linguistic backgrounds, as well as hyperlocal businesses serving niche markets.
Model | Fuzzy Match in Generation |
|---|---|
Google-Document-AI | 95.88 |
Gemini-2.0-Flash-001 | 96.53 |
Azure OCR | 97.31 |
Mistral OCR 2503 | 99.02 |
Benchmarks by language:
Language | Azure OCR | Google Doc AI | Gemini-2.0-Flash-001 | Mistral OCR 2503 |
|---|---|---|---|---|
ru | 97.35 | 95.56 | 96.58 | 99.09 |
fr | 97.50 | 96.36 | 97.06 | 99.20 |
hi | 96.45 | 95.65 | 94.99 | 97.55 |
zh | 91.40 | 90.89 | 91.85 | 97.11 |
pt | 97.96 | 96.24 | 97.25 | 99.42 |
de | 98.39 | 97.09 | 97.19 | 99.51 |
es | 98.54 | 97.52 | 97.75 | 99.54 |
tr | 95.91 | 93.85 | 94.66 | 97.00 |
uk | 97.81 | 96.24 | 96.70 | 99.29 |
it | 98.31 | 97.69 | 97.68 | 99.42 |
ro | 96.45 | 95.14 | 95.88 | 98.79 |
Fastest in its category
Being lighter weight than most models in the category, Mistral OCR performs significantly faster than its peers, processing up to 2000 pages per minute on a single node. The ability to rapidly process documents ensures continuous learning and improvement even for high-throughput environments.
Doc-as-prompt, structured output
Mistral OCR also introduces the use of documents as prompts, enabling more powerful and precise instructions. This capability allows users to extract specific information from documents and format it in structured outputs, such as JSON. Users can chain extracted outputs into downstream function calls and build agents. See this example notebook.
Available to self-host on a selective basis
For organizations with stringent data privacy requirements, Mistral OCR offers a self-hosting option. This ensures that sensitive or classified information remains secure within your own infrastructure, providing compliance with regulatory and security standards. If you would like to explore self-deployment with us, please let us know.
Use cases
We are empowering our beta customers to elevate their organizational knowledge by transforming their extensive document repositories into actions and solutions. Some of the key use cases where our technology is making a significant impact include:
Digitizing scientific research: Leading research institutions have been experimenting with Mistral OCR to convert scientific papers and journals into AI-ready formats, making them accessible to downstream intelligence engines. This has facilitated measurably faster collaboration and accelerated scientific workflows.
Preserving historical and cultural heritage: Organizations and nonprofits that are custodians of heritage have been using Mistral OCR to digitize historical documents and artifacts, ensuring their preservation and making them accessible to a broader audience.
Streamlining customer service: Customer service departments are exploring Mistral OCR to transform documentation and manuals into indexed knowledge, reducing response times and improving customer satisfaction.
Making literature across design, education, legal, etc. AI ready: Mistral OCR has also been helping companies convert technical literature, engineering drawings, lecture notes, presentations, regulatory filings and much more into indexed, answer-ready formats, unlocking intelligence and productivity across millions of documents.
Experience it today
Mistral OCR capabilities are free to try on le Chat. To try the API, head over to la Plateforme. We’d love to get your feedback; expect the model to continue to get even better in the weeks to come. As part of our strategic engagement programs, we will also offer on-premises deployment on a selective basis.