



In most large Rails monoliths, organizations prioritize writing new features over writing tests for them. Over time, more and more code goes untested, forcing teams to spend more time debugging painful bugs.
We built an autonomous agent that closes that gap. It reads Rails source files, generates or improves RSpec tests, validates them against style rules and coverage targets, and runs inside a CI/CD pipeline with no human intervention. To operate on codebases at this scale, it runs in parallel: multiple instances working on different files simultaneously.
RSpec through an agent's eyes
Ruby is dynamically typed: there is no compilation step, so errors surface at runtime. For our agent, this means the only way to verify test syntax is to execute it. RSpec, the standard Rails testing framework, makes tests expressive and readable, but its domain-specific language is easy to get wrong.
When the agent reads a Ruby on Rails codebase, it reads five main file types (models, serializers, controllers, mailers, helpers), each structured differently (therefore tested in different ways). The agent needs distinct instructions for each type.
One benefit: the mapping from source file to spec file is nearly 1:1. The general convention is:
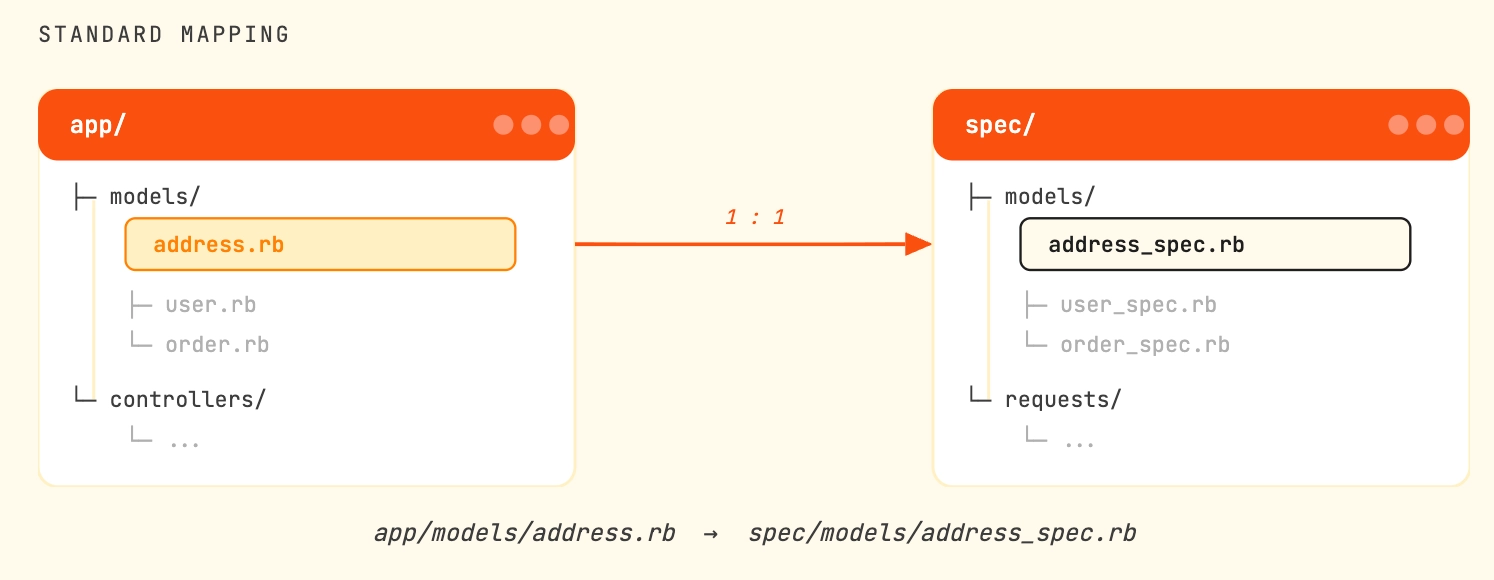
There are a few exceptions to that rule however, like that app/controllers/ are sometimes mapped to spec/requests/, or that sometimes a single source file can have multiple spec files, in which case the convention is:
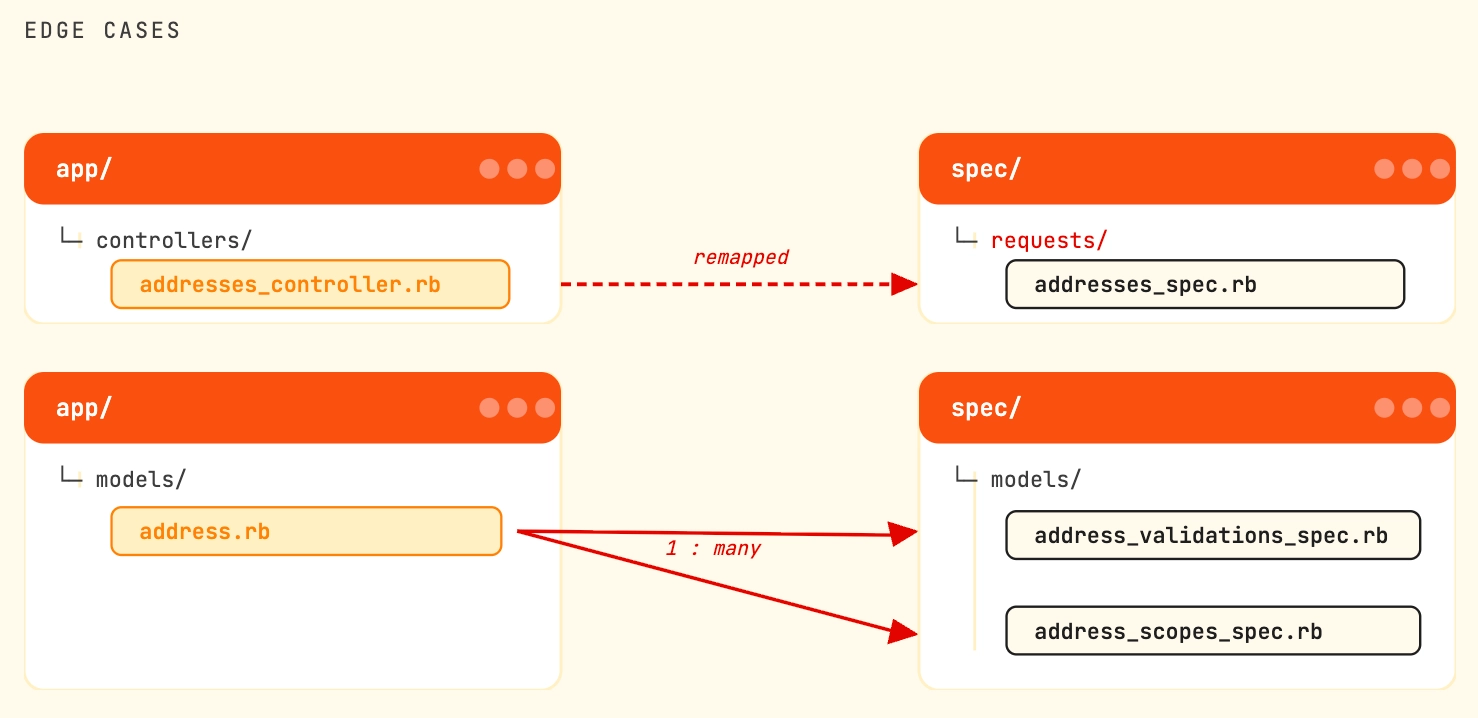
This straightforward mapping makes it easy to locate the tests for any given file, or to identify files that lack tests entirely.
Where it gets harder for our agent is that to avoid duplicating code, RSpec relies heavily on shared context: factories, fixtures, database schemas...
Factories: Reusable templates for creating test objects with predefined attributes, making it easy to generate consistent test data.
Fixtures: Static data files that preload test database records, providing a fixed baseline for tests.
If a factory file doesn’t exist, the agent creates it; if it does, the agent reuses it. Because factories are shared across many tests (unlike spec files), careless changes can easily break tests elsewhere, so updates to these files must be made with caution.
Building the agent with Vibe
We built the agent on top of Vibe, Mistral's open-source coding assistant. The default system prompt was sufficient for this project, so we focused on three levers: repository-level context, specialized skills, and custom tools.
Context engineering
Context engineering was central to our approach. Vibe supports a repository-level AGENTS.md file: when running on a repository with this file at its root, its contents are automatically appended to the system prompt.
The AGENTS.md we used provided basic details about the target repositories, but mostly, it provided the agent with a step-by-step execution plan:
1. Read the source file2. Read the documentation (if it exists)3. Check if a spec already exists4. Choose and read exactly one skill based on the source file location5. Find existing patterns, factories, and helpers6. Execute the skill (Extract → Factory → Generate tests)7. Validate with Rubocop tool8. Validate with SimpleCov toolEach step included details about what to do and what the success criteria are. We also included some best practices of RSpec on areas where we felt it was important to orient the agent. Example:
- **NEVER** use `be_present`, `be_truthy`, `be_between`, or `include(:key)`These are vague. Use `eq(exact_value)` alwaysWe found the agent would sometimes skip methods or leave edge cases untested: it would generate a spec that looked complete but quietly ignored a few public methods from the source file. To counter this, the AGENTS.md ends with a forced self-review: the agent must re-read the source file and explicitly ask itself "Did I test every public method? Count them." before finishing. If anything is missing, it goes back.
With this generic AGENTS.md file forcing the agent to follow strict planning, our quality score went from 0.68 to 0.74, all from a single markdown file with framework-level instructions.
Using SKILLS files:
Recall step 4 of our AGENTS.md:
4. Choose and read exactly one skill based on the source file location
A single generic skill would produce mediocre results: the instructions precise enough for testing a model file are the wrong instructions for a controller file.
What worked was creating a separate skills file for each category, plus one for plain Ruby files.
Here is an example of a basic skills file for testing controllers:
---name: "Generate Request Spec"description: "Generate RSpec request tests for a Rails controller. Use when the source file is in app/controllers/."---
# Generate Request Spec
## File Scope
- `spec/requests//_spec.rb` — drop `_controller` from the filename- `spec/factories/.rb` — create or update if needed
## Example tests for Controllers
# frozen_string_literal: truerequire 'rails_helper'
describe 'Admin::Users', type: :request do let(:user) { create(:user, :admin) } before { sign_in user }
# Unauthorized access — one test per action describe '#authorized?' do let(:user) { create(:user) } it 'GET /admin/users redirects' do get '/admin/users' expect(response).to have_http_status(:redirect) end end
# Each action: happy + sad paths describe 'POST /admin/users' do let(:valid_params) { { user: attributes_for(:user) } } let(:invalid_params) { { user: { email: '' } } }
context 'with valid params' do it 'creates a record' do expect { post '/admin/users', params: valid_params }.to change(User, :count).by(1) expect(response).to have_http_status(:created) end end
context 'with invalid params' do it 'returns unprocessable entity with errors' do post '/admin/users', params: invalid_params expect(response).to have_http_status(:unprocessable_entity) json = JSON.parse(response.body, symbolize_names: true) expect(json[:errors]).to include("Email can't be blank") end end endend
## Critical Rules
- **Assert content, not just status:** always parse JSON and verify exact values- **Test exact error messages:** `include("Email can't be blank")`, not `be_present`- **Verify state changes:** use `.by(1)` and check the created record's attributes- **Cover all actions:** index, show, create, update, destroy, and any custom actions- **Test auth on every action:** verify unauthorized users get the correct status code- Use `let` only, never `@instance_variables`; `sign_in user` again before `follow_redirect!`Adding custom tools
Vibe has built-in tools for reading and writing files, running bash commands, and editing code. But it also supports custom tools & MCPs to expand its action space. For this project, custom tools were key.
After some experimentation, we went for:
A RuboCop linting tool that runs the
rubocopcommand to detect style violations, so that the agent goes back to the code and fixes them.A SimpleCov tool integrated with RSpec that checks both code coverage and test correctness. Placing this as the final step was key: it guarantees every test the agent writes actually runs.
Below is a stripped-down version of how we implemented the Rubocop linting tool:
import asynciofrom pathlib import Path
from pydantic import BaseModelfrom vibe.core.tools.base import BaseTool, ToolError
class RubocopLintResult(BaseModel): command: str output: str success: bool exit_code: int | None = None
class RubocopLint(BaseTool): description = "Lint spec files using Rubocop."
async def run(self, spec_path: str): spec_path = Path(spec_path)
cmd = ["rubocop", "--format", "simple", str(spec_path)] proc = await asyncio.create_subprocess_exec( *cmd, stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.PIPE )
try: stdout, stderr = await asyncio.wait_for(proc.communicate(), timeout=60) except TimeoutError: proc.kill() await proc.wait() raise ToolError("Rubocop timed out after 60s")
output = stdout.decode("utf-8", errors="ignore")
yield RubocopLintResult( command=" ".join(cmd), output=output, success=proc.returncode == 0, exit_code=proc.returncode )The SimpleCov tool follows the same pattern but does more: it runs the spec file with RSpec, collects pass/fail results for each test, and reports the coverage percentage of the source file. The agent gets back which tests failed (with error messages), and which lines of the source file were never exercised. This gives it enough to self-correct when needed.
When we first wired this tool in, only around a third of generated tests passed on first execution. The agent self-corrected all failures within a few iterations. Without this step, some of those tests would not have ran.
Measuring test quality
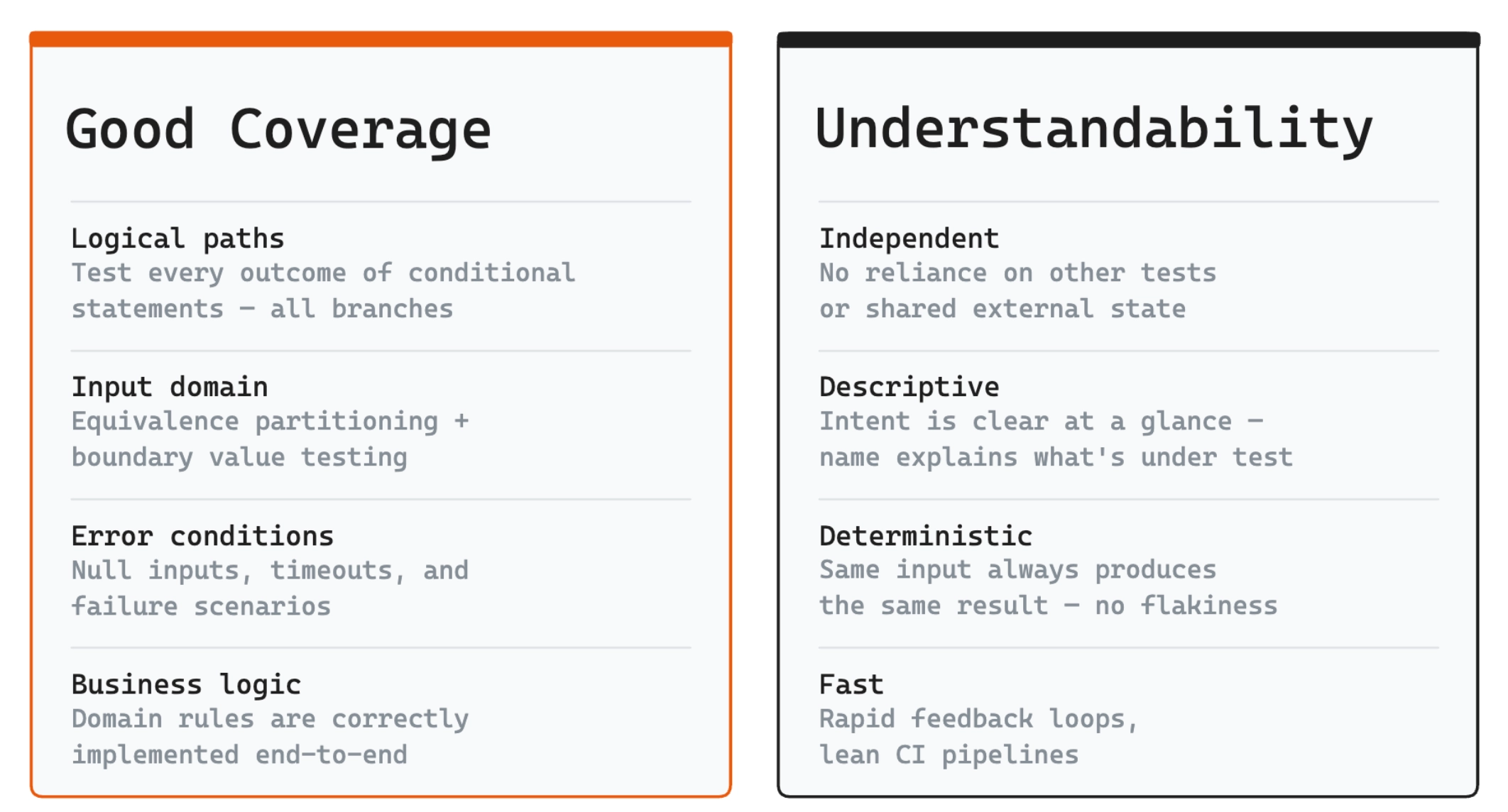
A good unit test follows the Arrange-Act-Assert pattern: set up state, execute one behavior, verify the outcome. It should use precise assertions, cover both happy and error paths, and produce failures that clearly identify what broke.
Tool-based metrics
Existing Ruby on Rails tools allow us to get several metrics easily:
RSpec: the most popular testing framework for Ruby. Expressive syntax for writing readable, well-structured tests.
RuboCop: a static Ruby code analyzer and formatter, helping enforce style guidelines and keeping code consistent
SimpleCov: a code coverage tool for Ruby, measuring how much code is executed by the test suite.
From these tools, we can extract several useful quantitative metrics: the proportion of tests that pass, the number of RuboCop violations per file, the proportion of code covered by the unit test suite, and the speed of execution. These metrics provide a solid baseline for measuring the overall performance of a test suite.
But these numbers alone cannot determine whether a test file is actually good. How should we compare two files that both have zero RuboCop violations, 100% coverage, and all tests passing? The quantitative metrics may look identical, yet qualitative differences in test quality can still exist.
LLM-as-a-judge
The idea behind LLM-as-a-judge is to ask an LLM: “Are all error conditions tested?” or “Is this a good test?” and get back a score from 0 to 1 based on clear criteria.
Example prompt:
## Good Tests
Precise values: `eq(100)`, not `be_present` or `be_a(Float)`.State changes: `change { User.count }.by(1)`.Error paths: `raise_error(ArgumentError, "message")`.Boundary cases: Test exact values at thresholds (e.g., `page(0)`).Public interface: No `.send(:private_method)`.
## Bad Tests
Vague assertions: `be_truthy`, `be_an(Array)`."Doesn't crash" tests: `not_to raise_error`.Testing private methods.Over-mocking (tests mocks, not behavior).No assertions on return values.
## Scoring Rules
- 1.0: Precise assertions on return values/state + all key paths covered (happy, error, boundaries).- 0.8: Precise assertions on all tested paths, but 1-2 edge cases missing entirely.- 0.6: All key paths covered, but 1-2 tests use vague assertions (e.g., `be_truthy` instead of `eq(expected)`) or minor over-mocking.- 0.4: Some tests have precise assertions; others are vague, over-mocked, or skip return value checks.- 0.2: Most tests lack meaningful assertions: vague matchers, stubbed-out logic, no verification of actual output.- 0.0: Tests are structurally broken: testing private methods, no real assertions, or verifying mocks instead of behavior.The "Scoring Rules" section here is especially important as it enforces the score to be more consistent across runs. Without it, the agent would lack clear definition of how strict or how lax the scoring is.
Such a score is less authoritative than a tool's output or a thorough developer review. But it is a good indication of how well the current version of our agent is doing, especially when run at scale across every file in a repository.
Limitations of LLM-as-a-judge evaluation:
Anything that can be put into text can be scored with LLM-as-a-judge, which makes it versatile. But the score output is not deterministic. Even with temperature=0, there will be variance due to the order of kernel operations. In practice the outputs for the same evaluation are always close, but this lack of determinism can be an issue for some use cases.
For our use case, since we score not a single test but usually tens to hundreds at a time, this was an acceptable limitation. The aggregated score stayed consistent.
The missing parenthesis problem
There was another core problem with LLM-as-a-judge: a test can be of great quality but not run, or have the logic behind it be wrong altogether.
Example:
RSpec.describe User, "#full_name" do it "combines first and last name with a space" do user = User.new(first_name: "Ada", last_name: "Lovelace"
expect(user.full_name).to eq("Ada Lovelace") endendThis test looks great. It tests one behavior, has a clear description that reads as documentation, follows Arrange-Act-Assert:, and would fail with a useful message if broken.
We ran this test through multiple models using the scoring prompt defined earlier. The average score given was 0.75. A developer taking a quick look would likely agree.
But this test has one core flaw: it will not run. All because of a missing closing parenthesis ) on the User.new(). This is a critical flaw that makes this test definitely not suitable.
This example is easy to mitigate. But there are a lot other possibilities that can lead to syntax error:
Versioning errors: Using methods or syntax from an incompatible Ruby or Rails version
Non-existent methods: some methods might have been removed, renamed, or never existed.
Factory/fixture errors: Referencing missing factories, incorrect attributes, or missing associations
Missing dependencies: Using gems or modules not included in the test environment
The experiment
We ran an experiment to check the agent could hold up against a real codebase. The target repository contained 275 source files. Half of them already had test coverage. The other half had none.
We pointed the agent at every file, whether it already had tests or not. For uncovered files, it generated specs from scratch successfully. For files that already had tests, it rewrote and improved them.
We scored every spec file before and after with LLM-as-a-judge. The aggregate score for tested files went from 0.49 to 0.74, and coverage reached 100%. There's still room for improvement, but the results validated the approach.
Metric | Result |
|---|---|
Files processed | 275 |
Tests passing | 100% |
Average line coverage (SimpleCov) | 100% |
RuboCop violations after self-correction | 0 |
LLM-as-a-judge score | 0.74 |
By file type
Not all file types were easy to test. Models scored highest: their business logic is self-contained and the test patterns are predictable. Controllers were harder, HTTP request handling introduced more room for error.
File type | LLM-as-a-judge |
|---|---|
Models | 0.81 |
Controllers | 0.67 |
Serializers | 0.80 |
Does it run?
Bundling SimpleCov with RSpec execution as the final step, forcing the agent to run every test it wrote, was the single most impactful decision. Only a third of tests passed on first execution. The agent self-corrected all failures within a few iterations.
Without this step, LLM-as-a-judge would have rated these non-running tests as high quality: the missing parenthesis problem at scale.
Vibe is open source. The agent, tools, and skills described here all run on top of it. Try it now.